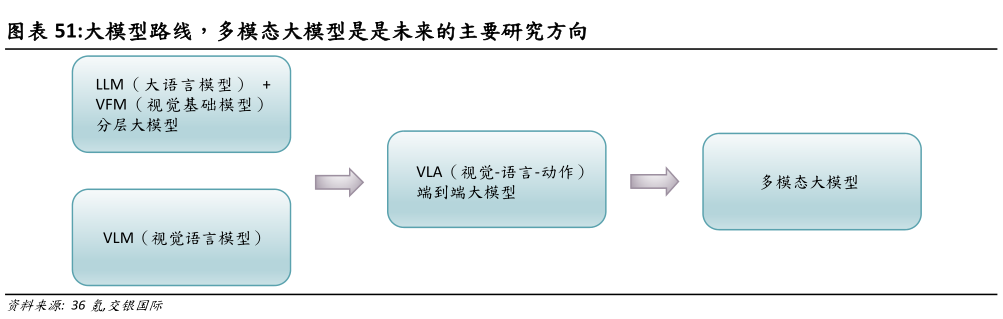
> 数据图表一起讨论下大模型路线,多模态大模型是是未来的主要研究方向
2025-4-3 VLA(视觉-语言-动作)端到端大模型。视觉-语言-动作(VLA)模型将视觉、语言和动作三种模态融合,形成端到端的模型。该模型能够从视觉输入和语言指令中直接生成动作指令,实现复杂任务的自主执行。例如,Google DeepMind 的 Robotic Transformer 2(RT-2)就是典型的 VLA 模型。 多模态大模型:多模态大模型旨在处理多种模态的数据,如文本、图像、音频等。通过联合训练,这些模型能够在不同模态之间进行信息融合,实现更复杂的任务。在机器人领域,多模态大模型使机器人能够综合处理来自不同传感器的数据,提升其感知和决策能力,是目前主要研究方向。