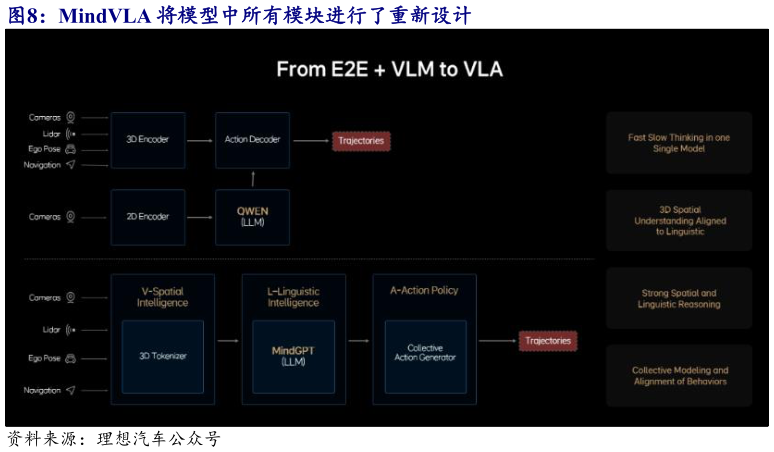
> 数据图表咨询大家MindVLA 将模型中所有模块进行了重新设计2025-3-63 月 18 日,理想汽车在 NVIDIA GTC 2025 大会上推出 MindVLA 大模型。VLA(视觉-语言-行动)模型是机器人大模型的新范式,其将赋予自动驾驶强大的 3D 空间理解能力、逻辑推理能力和行为生成能力,让自动驾驶能够感知、思考和适应环境,已成为 2025 年智能驾驶领域的重要技术竞争方向。理想自研的 MindVLA 没有简 单 地 将 端 到 端 模 型 和 VLM 模 型 结 合 在 一 起 , 而 是 全 新 设 计 了 所 有 模块 。MindVLA 不仅能够理解复杂的 3D 空间环境,还能进行逻辑推理,并据此制定合理的驾驶决策,从而让车辆真正具备感知、思考和自主行动的能力。开源证券综合其他