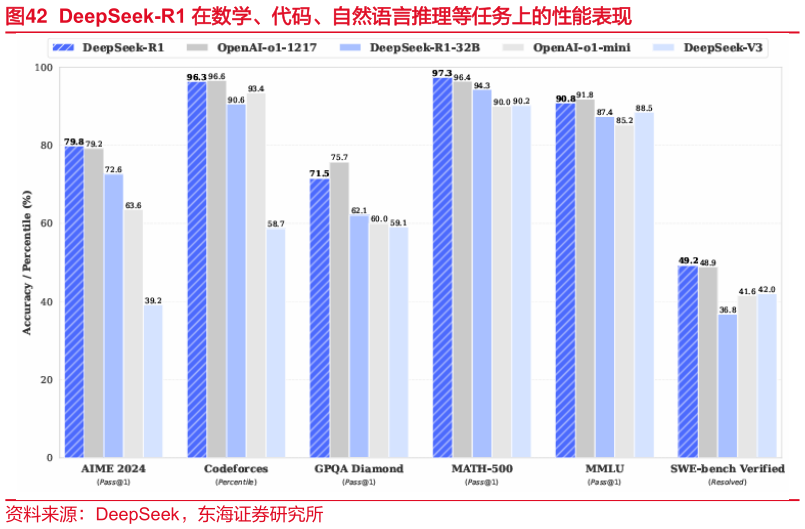
> 数据图表咨询大家DeepSeek-R1 在数学、代码、自然语言推理等任务上的性能表现2025-3-4值。这种压缩-解压缩机制使得模型可以在显著减少内存占用的同时,保持甚至提升性能。DeepSeek-V2 的技术报告显示,MLA 使 KV 缓存减少了 93.3%,训练成本节省了 42.5%,生成吞吐量提高了 5.76 倍。2)DeepSeekMoE 的基本架构建立在 Transformer 框架之上,在前馈网络(FFN)层引入了创新的 MoE 机制。与传统 MoE 使用较粗粒度的专家划分不同,DeepSeekMoE 采用了更细粒度的专家划分方式,使每个专家能够负责更具体的任务,从而提高模型的灵活性和表达能力。具体来说,DeepSeekMoE 的每个 MoE 层由 1 个共享专家和 256 个路由专家组成,每个 token 会激活 8 个路由专家。这种设计使得模型能够在保持高性能的同时,显著减少计算资源的消耗。不同于传统 MoE 中专家都是独立的设计,DeepSeekMoE 的共享专家负责处理所有 token 的通用特征,而路由专家则根据 token 的具体特征进行动态分配。这种分工不仅减少了模型的冗余、提高了计算效率,还使得模型能够更好地处理不同领域的任务。东海证券综合其他