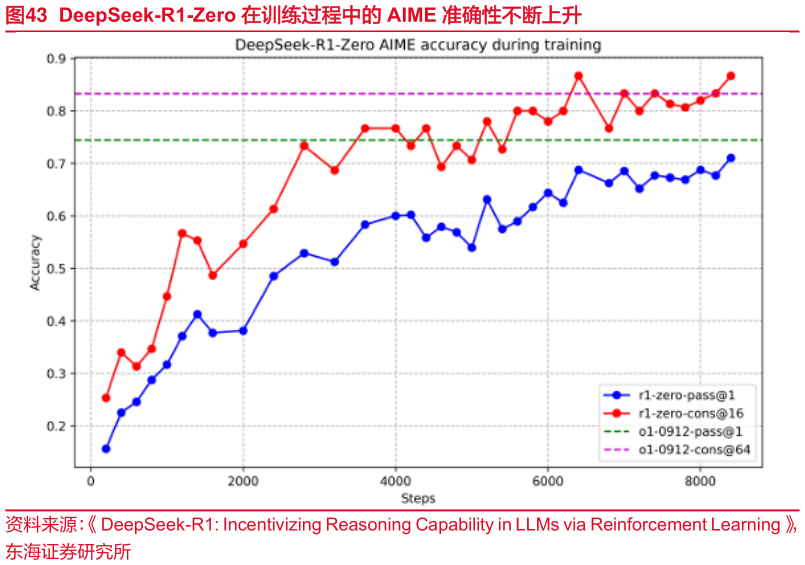
> 数据图表想关注一下DeepSeek-R1-Zero 在训练过程中的 AIME 准确性不断上升2025-3-4的情况。在自我进化的过程中,随着推理运算时间的增加,模型解决复杂推理任务的能力也在不断增强,此外还涌现出了“反思”等复杂行为,模型会重新审视和评估自己先前的步骤,还会自发地探索解决问题的其他方法。R1-Zero 虽然推理能力强,但存在推理过程可读性差、语言混杂等问题,因此 DeepSeek-R1 在 R1-Zero 的基础上引入了“冷启动”策略和多阶段训练,冷启动是指先用少量高质量的 CoT 数据对模型进行初步训练,相当于给模型一个“热身”,目标是让模型既能保持强大的推理能力,又能生成清晰、用户友好的回答。东海证券综合其他