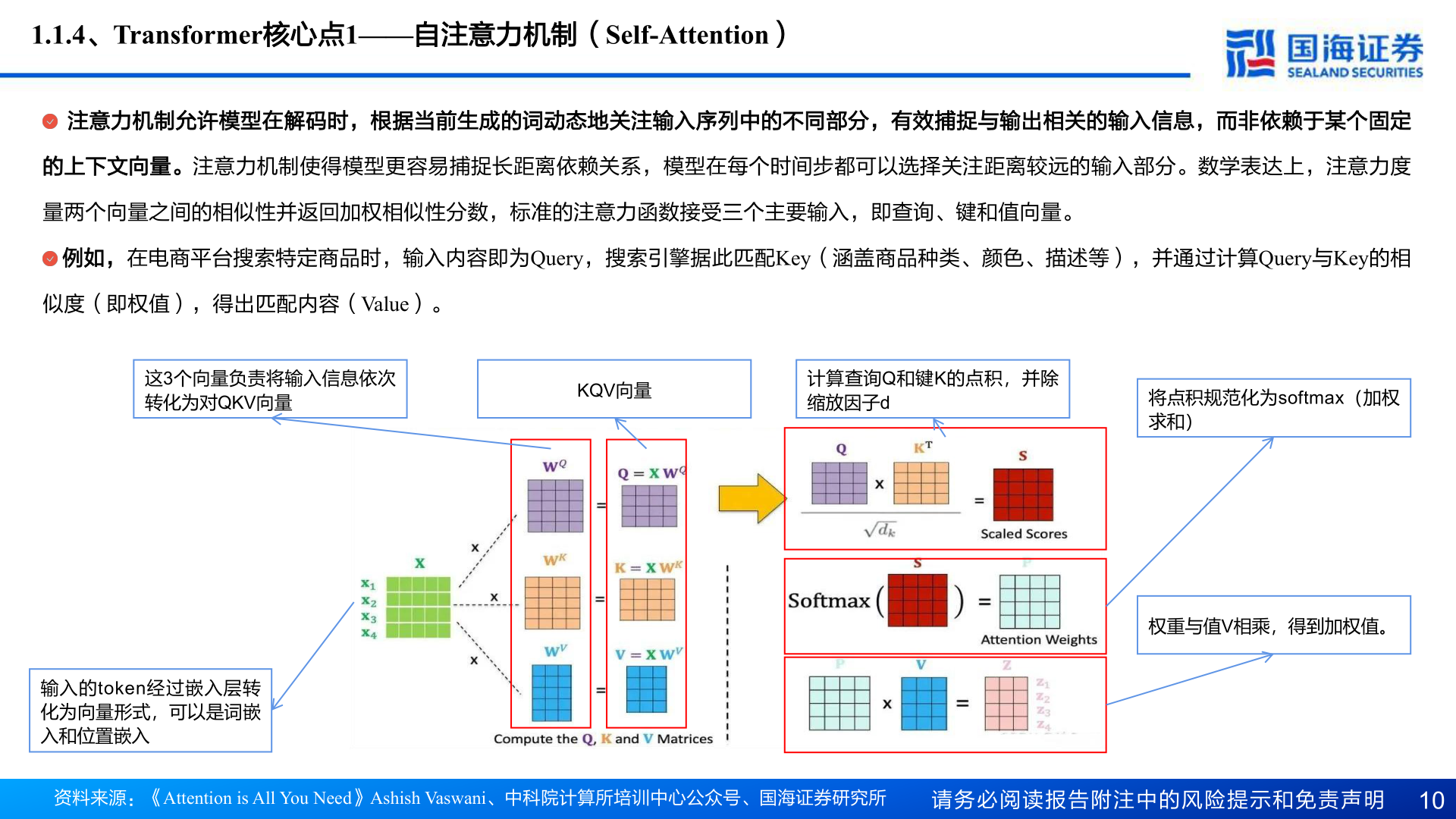
> 数据图表如何了解1.1.4、Transformer核心点1——自注意力机制(Self-Attention)
2025-4-11.1.4、Transformer核心点1——自注意力机制(Self-Attention)注意力机制允许模型在解码时,根据当前生成的词动态地关注输入序列中的不同部分,有效捕捉与输出相关的输入信息,而非依赖于某个固定的上下文向量。注意力机制使得模型更容易捕捉长距离依赖关系,模型在每个时间步都可以选择关注距离较远的输入部分。数学表达上,注意力度量两个向量之间的相似性并返回加权相似性分数,标准的注意力函数接受三个主要输入,即查询、键和值向量。例如,在电商平台搜索特定商品时,输入内容即为Query,搜索引擎据此匹配Key(涵盖商品种类、颜色、描述等),并通过计算Query与Key的相似度(即权值),得出匹配内容(Value)。这3个向量负责将输入信息依次转化为对QKV向量KQV向量计算查询Q和键K的点积,并除缩放因子d将点积规范化为softmax(加权求和)输入的token经过嵌入层转化为向量形式,可以是词嵌入和位置嵌入资料来源:《Attention is All You Need》Ashish Vaswani、中科院计算所培训中心公众号、国海证券研究所请务必阅读报告附注中的风险提示和免责声明 10权重与值V相乘,得到加权值。