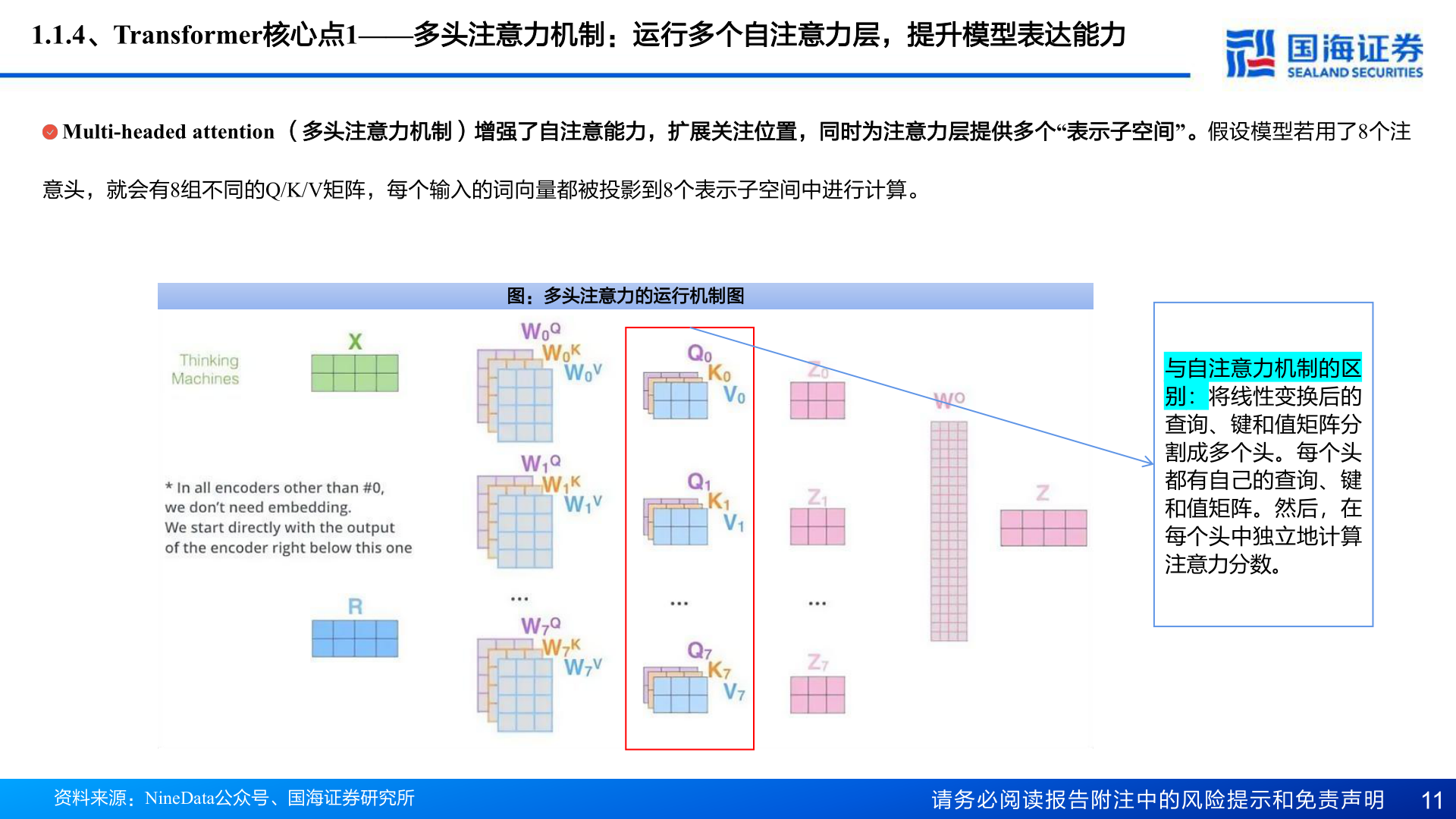
> 数据图表各位网友请教一下1.1.4、Transformer核心点1——多头注意力机制:运行多个自注意力层,提升模型表达能力2025-4-11.1.4、Transformer核心点1——多头注意力机制:运行多个自注意力层,提升模型表达能力Multi-headed attention (多头注意力机制)增强了自注意能力,扩展关注位置,同时为注意力层提供多个“表示子空间”。假设模型若用了8个注意头,就会有8组不同的Q/K/V矩阵,每个输入的词向量都被投影到8个表示子空间中进行计算。图:多头注意力的运行机制图与自注意力机制的区别:将线性变换后的查询、键和值矩阵分割成多个头。每个头都有自己的查询、键和值矩阵。然后,在每个头中独立地计算注意力分数。资料来源:NineData公众号、国海证券研究所请务必阅读报告附注中的风险提示和免责声明 11国海证券综合其他