> 数据图表我想了解一下1.2.1、预训练Transformer模型时代 (2018–2020):GPT VS BERT
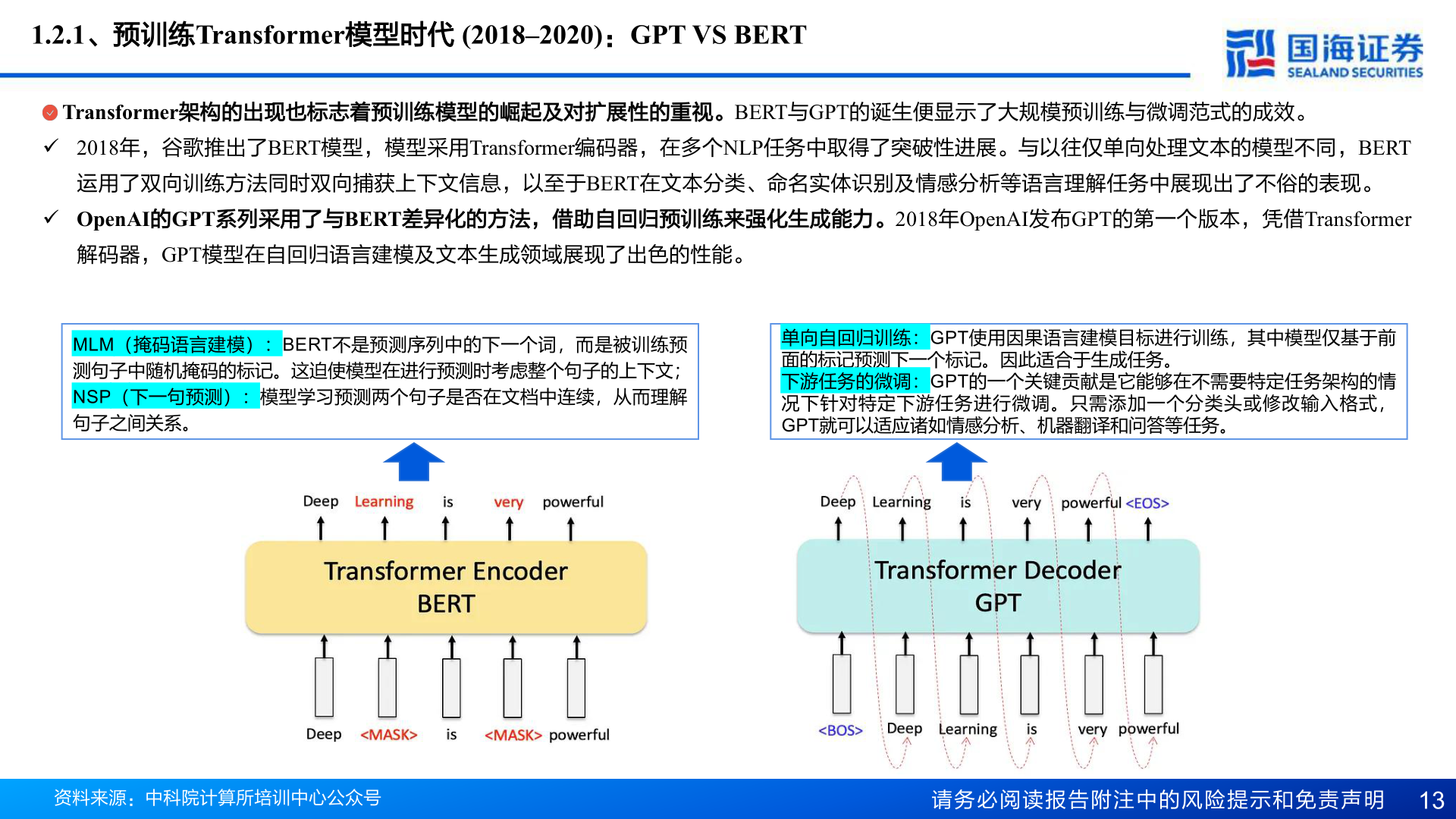
2025-4-11.2.1、预训练Transformer模型时代 (2018–2020):GPT VS BERTTransformer架构的出现也标志着预训练模型的崛起及对扩展性的重视。BERT与GPT的诞生便显示了大规模预训练与微调范式的成效。 2018年,谷歌推出了BERT模型,模型采用Transformer编码器,在多个NLP任务中取得了突破性进展。与以往仅单向处理文本的模型不同,BERT运用了双向训练方法同时双向捕获上下文信息,以至于BERT在文本分类、命名实体识别及情感分析等语言理解任务中展现出了不俗的表现。 OpenAI的GPT系列采用了与BERT差异化的方法,借助自回归预训练来强化生成能力。2018年OpenAI发布GPT的第一个版本,凭借Transformer解码器,GPT模型在自回归语言建模及文本生成领域展现了出色的性能。MLM(掩码语言建模):BERT不是预测序列中的下一个词,而是被训练预测句子中随机掩码的标记。这迫使模型在进行预测时考虑整个句子的上下文;NSP(下一句预测):模型学习预测两个句子是否在文档中连续,从而理解句子之间关系。单向自回归训练:GPT使用因果语言建模目标进行训练,其中模型仅基于前面的标记预测下一个标记。因此适合于生成任务。下游任务的微调:GPT的一个关键贡献是它能够在不需要特定任务架构的情况下针对特定下游任务进行微调。只需添加一个分类头或修改输入格式,GPT就可以适应诸如情感分析、机器翻译和问答等任务。资料来源:中科院计算所培训中心公众号请务必阅读报告附注中的风险提示和免责声明 13