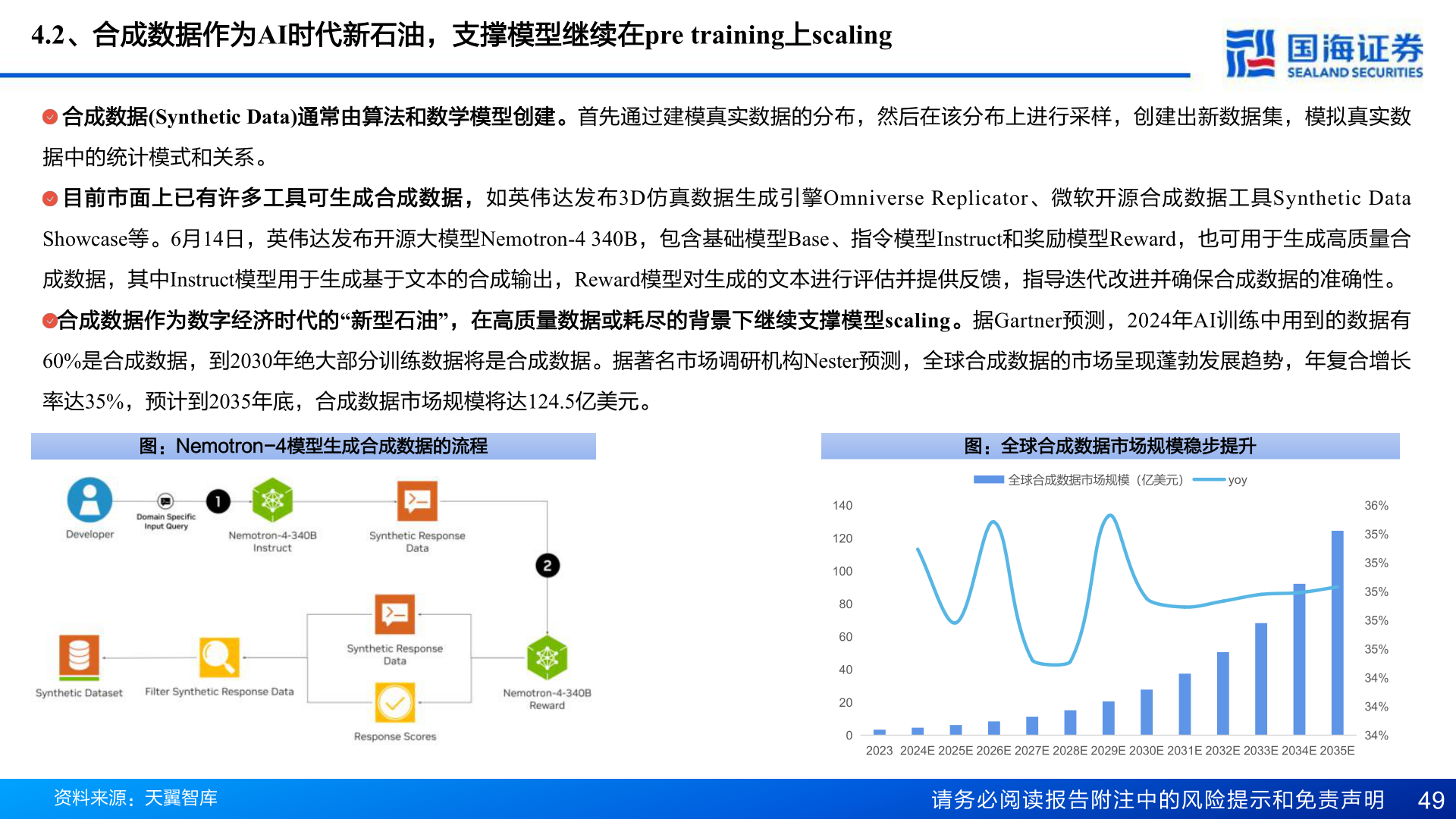
> 数据图表咨询大家4.2、合成数据作为AI时代新石油,支撑模型继续在pre training上scaling2025-4-14.2、合成数据作为AI时代新石油,支撑模型继续在pre training上scaling合成数据(Synthetic Data)通常由算法和数学模型创建。首先通过建模真实数据的分布,然后在该分布上进行采样,创建出新数据集,模拟真实数据中的统计模式和关系。目前市面上已有许多工具可生成合成数据,如英伟达发布3D仿真数据生成引擎Omniverse Replicator、微软开源合成数据工具Synthetic Data Showcase等。6月14日,英伟达发布开源大模型Nemotron-4 340B,包含基础模型Base、指令模型Instruct和奖励模型Reward,也可用于生成高质量合成数据,其中Instruct模型用于生成基于文本的合成输出,Reward模型对生成的文本进行评估并提供反馈,指导迭代改进并确保合成数据的准确性。合成数据作为数字经济时代的“新型石油”,在高质量数据或耗尽的背景下继续支撑模型scaling。据Gartner预测,2024年AI训练中用到的数据有60%是合成数据,到2030年绝大部分训练数据将是合成数据。据著名市场调研机构Nester预测,全球合成数据的市场呈现蓬勃发展趋势,年复合增长率达35%,预计到2035年底,合成数据市场规模将达124.5亿美元。图:Nemotron-4模型生成合成数据的流程图:全球合成数据市场规模稳步提升全球合成数据市场规模(亿美元)yoy14012010080604020036%35%35%35%35%35%34%34%34%2023 2024E 2025E 2026E 2027E 2028E 2029E 2030E 2031E 2032E 2033E 2034E 2035E资料来源:天翼智库请务必阅读报告附注中的风险提示和免责声明 49国海证券综合其他