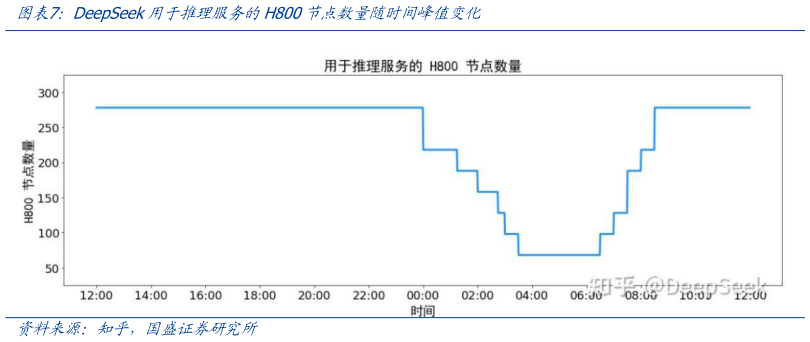
> 数据图表想问下各位网友DeepSeek用于推理服务的H800节点数量随时间峰值变化2025-5-0当用户与 Agent 进行多轮对话,或者要求 Agent 处理长文档、分析大量数据时,模型需要维持庞大的上下文信息。不仅仅是用户输入的文本,还可能包括系统提示、通过检索增强生成(RAG)从外部数据源获取的补充信息等。所有这些信息都需要在模型的工作记忆中占据空间。 Agent 接入外部数据的能力,例如通过 API 调用、网页浏览、数据库查询等方式获取实时或特定领域信息,进一步加剧了算力消耗。Agent 执行这些外部调用本身就需要计算资源,而获取到的外部数据往往需要整合到当前的上下文中,再次增加了上下文的长度和处理的复杂度。 2、Agent 执行任务验证带来的算力开销 为了确保 Agent 执行任务的准确性、可靠性和合规性,复杂的验证过程成为许多高级Agent 架构中不可或缺的一环。据 51cto,以 Manus AI 为例,其技术架构中包含一个专门的验证模块,验证模块通过三重校验体系保障输出可靠性:逻辑验证器检测任务链的因果合理性事实核查器交叉比对多信源数据真实性合规审查器确保输出符合法律法规。在医疗咨询、金融分析等对准确性和合规性要求极高的场景中,验证模块发挥着关键作用,如在医疗咨询时同步验证医学指南、最新论文和临床数据,生成置信度评分,让输出结果精准且可靠。 执行这些验证步骤需要额外的计算资源,是为了提升结果质量和可靠性而进行的投入。我们认为 Agent 越智能、越可靠,其内置的验证和修正机制往往越复杂,对算力的需求也就越大。 3、多模态的发展会带来更大算力需求 随着技术进步,Agent 正朝着多模态的方向发展,即能够处理和整合多种类型的数据,如文本、图像、音频、视频等。多模态的发展使得 Agent 能够在更广泛的应用场景中发挥作用,为用户提供更加丰富和全面的交互体验,但同时也带来了更大的算力需求。以一个智能客服 Agent 为例,它不仅需要理解用户的文本提问,还可能需要识别用户上传的图片或语音消息。为了处理这些多模态数据,Agent 需要大量的计算资源, 4、算力瓶颈影响 Agent 服务的用户体验 在用户量激增、模型复杂度提升、应用场景多样化的背景下,算力瓶颈问题日益凸显,具体表现为服务响应延迟、服务不稳定甚至服务中断等情况,导致用户体验受损,虽然可以通过优化 API 调用方式(如批量请求、异步请求)等方法缓解,但根本原因在于瞬时或持续的算力需求超出了服务提供商的承载能力。 如据新京报贝壳财经记者测试发现 Manus 回答问题一般耗时 15 分钟,根据任务难度的不同,Manus 执行任务的时间也不同,如对“设计采访提纲与视频采访脚本方案”等几项文字类任务,Manus 的执行时间约为 15 分钟至 20 分钟,而对于“设计金融科普互动产品”这项涉及网页交互的任务,Manus 耗时 31 分钟。极客公园测试,用扣子的探索模式制定一份日本旅行攻略,做出这份旅行攻略的时间在 10 分钟以上, 同时为了保证用户体验 Agent 服务需要留出一定应对用户流量波动的冗余算力。用户对服务的访问量往往具有不确定性,会因各种因素如节假日、特殊事件、营销活动等出现峰值。DeepSeek 官方在知乎发布的技术报告指出,由于白天的服务负荷高,晚上的服务负荷低,因此 DeepSeek 实现了一套机制,在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。但并非所有 Agent服务提供商都有训练模型等需求可以充分利用闲时算力,因此能满足用户峰值的算力必然会存在一定的冗余。国盛证券综合其他