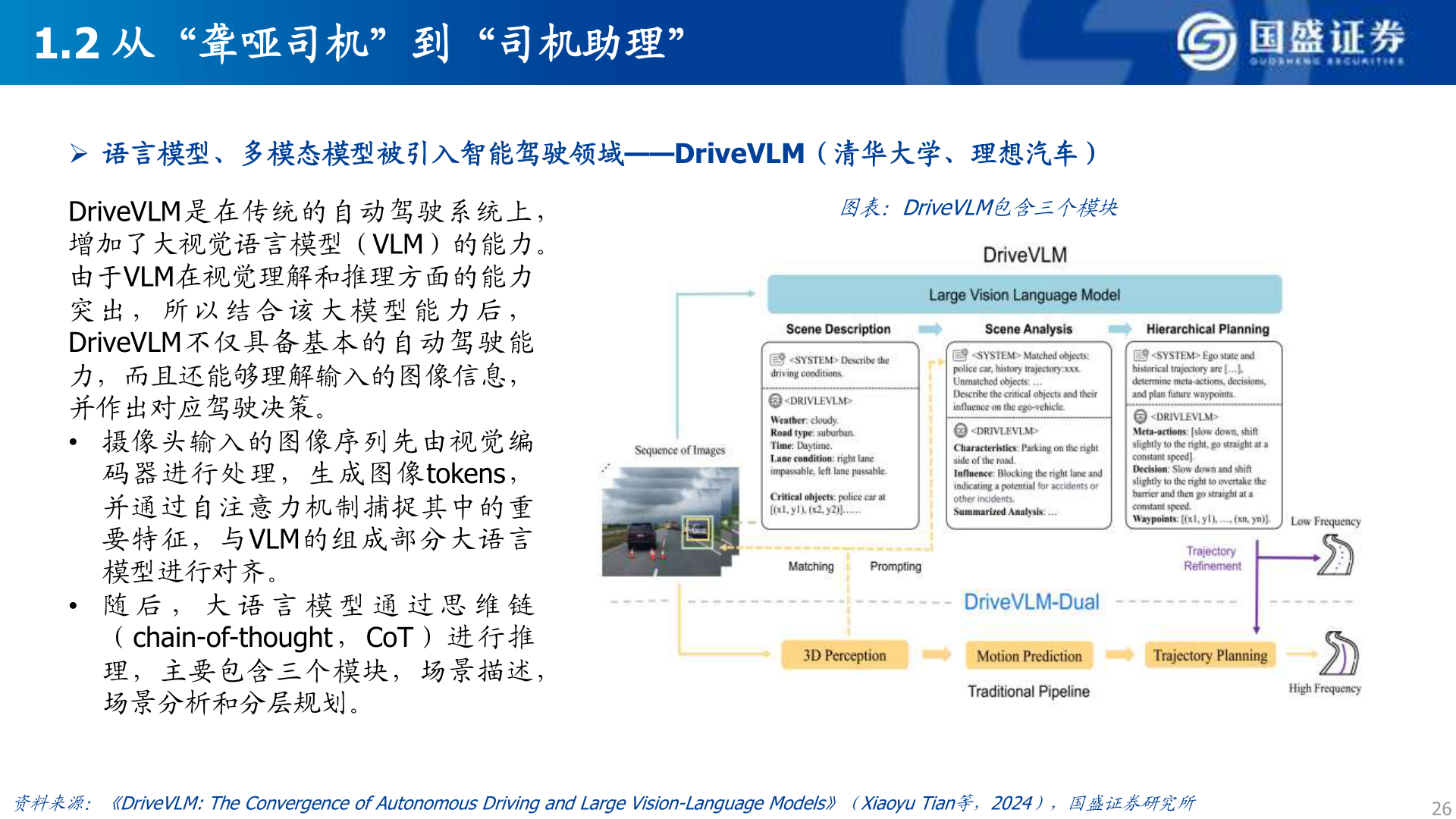
> 数据图表想关注一下1.2 从“聋哑司机”到“司机助理”2025-5-01.2 从“聋哑司机”到“司机助理”➢ 语言模型、多模态模型被引入智能驾驶领域——DriveVLM(清华大学、理想汽车)图表:DriveVLM包含三个模块DriveVLM是在传统的自动驾驶系统上,增加了大视觉语言模型(VLM)的能力。由于VLM在视觉理解和推理方面的能力突 出 , 所 以 结 合 该 大 模 型 能 力 后 ,DriveVLM不仅具备基本的自动驾驶能力,而且还能够理解输入的图像信息,并作出对应驾驶决策。• 摄像头输入的图像序列先由视觉编码器进行处理,生成图像tokens,并通过自注意力机制捕捉其中的重要特征,与VLM的组成部分大语言模型进行对齐。• 随 后 , 大 语 言 模 型 通 过 思 维 链( chain-of-thought , CoT ) 进 行 推理,主要包含三个模块,场景描述,场景分析和分层规划。资料来源:《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》(XiaoyuTian等,2024),国盛证券研究所26国盛证券科技传媒