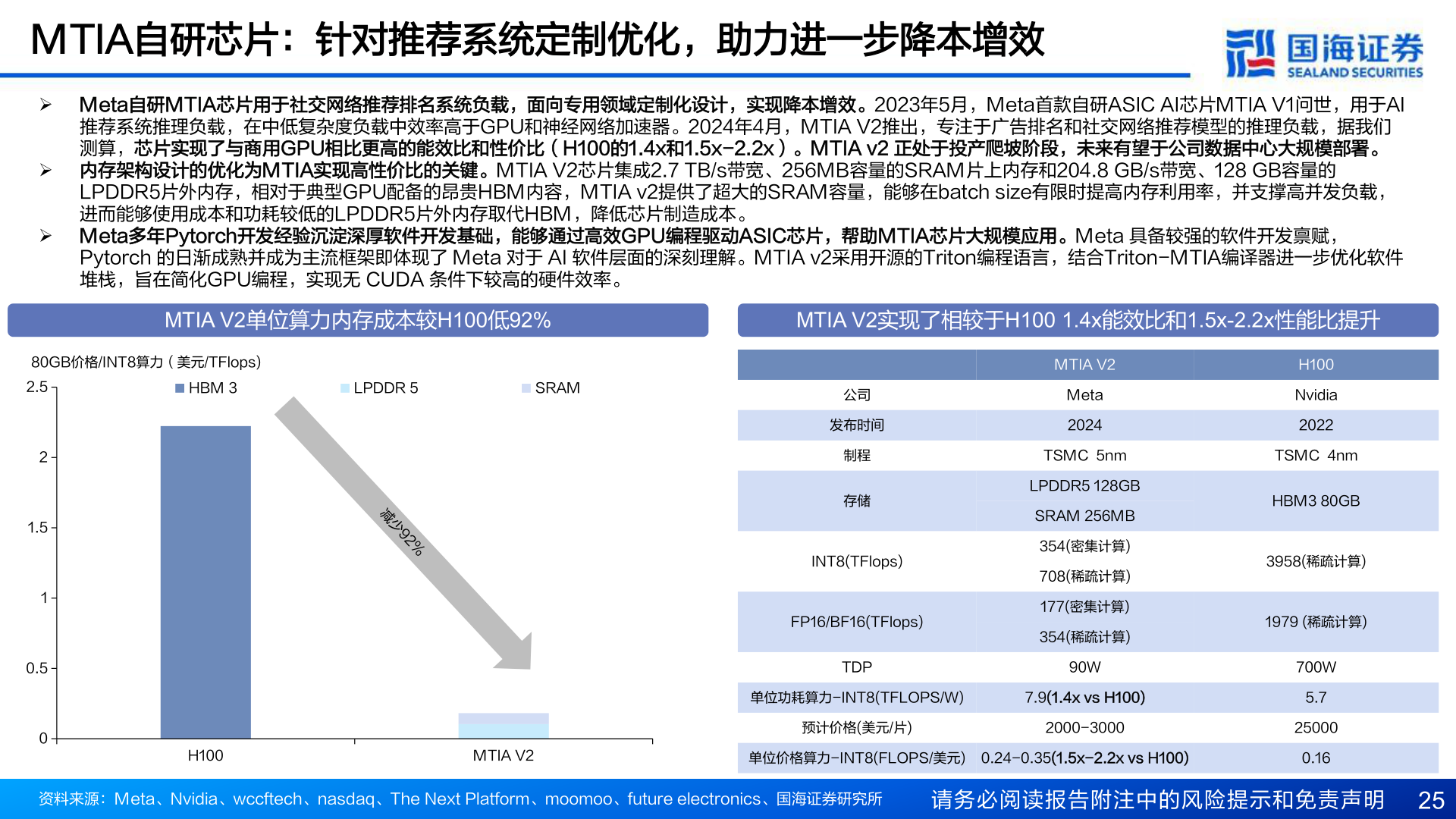
> 数据图表谁知道MTIA自研芯片:针对推荐系统定制优化,助力进一步降本增效
2025-5-5