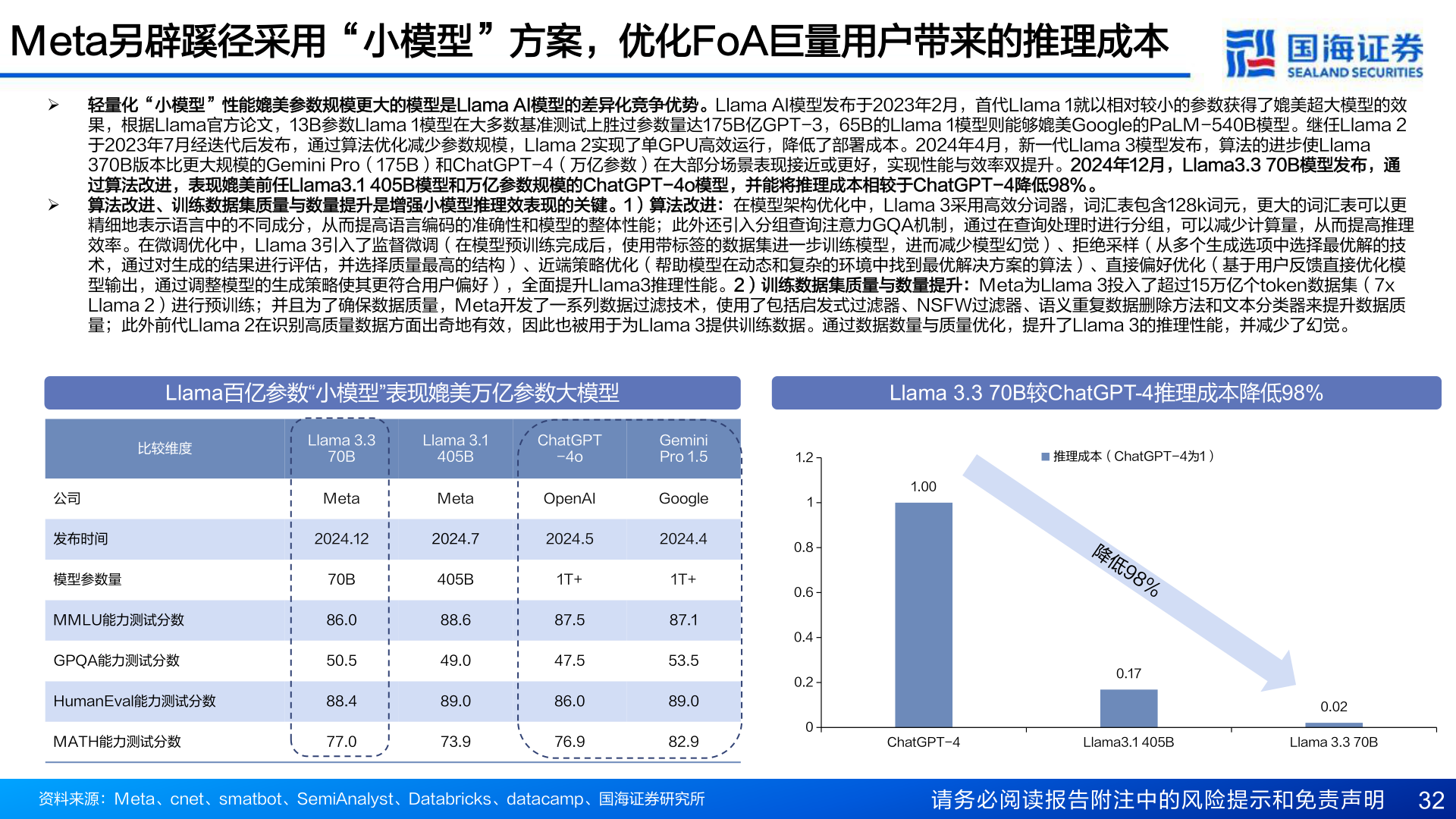
> 数据图表谁知道Meta另辟蹊径采用“小模型”方案,优化FoA巨量用户带来的推理成本2025-5-5Meta另辟蹊径采用“小模型”方案,优化FoA巨量用户带来的推理成本Ø 轻量化“小模型”性能媲美参数规模更大的模型是Llama AI模型的差异化竞争优势。Llama AI模型发布于2023年2月,首代Llama 1就以相对较小的参数获得了媲美超大模型的效果,根据Llama官方论文,13B参数Llama 1模型在大多数基准测试上胜过参数量达175B亿GPT-3,65B的Llama 1模型则能够媲美Google的PaLM-540B模型。继任Llama 2于2023年7月经迭代后发布,通过算法优化减少参数规模,Llama 2实现了单GPU高效运行,降低了部署成本。2024年4月,新一代Llama 3模型发布,算法的进步使Llama 370B版本比更大规模的Gemini Pro(175B)和ChatGPT-4(万亿参数)在大部分场景表现接近或更好,实现性能与效率双提升。2024年12月,Llama3.3 70B模型发布,通过算法改进,表现媲美前任Llama3.1 405B模型和万亿参数规模的ChatGPT-4o模型,并能将推理成本相较于ChatGPT-4降低98%。Ø 算法改进、训练数据集质量与数量提升是增强小模型推理效表现的关键。1)算法改进:在模型架构优化中,Llama 3采用高效分词器,词汇表包含128k词元,更大的词汇表可以更精细地表示语言中的不同成分,从而提高语言编码的准确性和模型的整体性能;此外还引入分组查询注意力GQA机制,通过在查询处理时进行分组,可以减少计算量,从而提高推理效率。在微调优化中,Llama 3引入了监督微调(在模型预训练完成后,使用带标签的数据集进一步训练模型,进而减少模型幻觉)、拒绝采样(从多个生成选项中选择最优解的技术,通过对生成的结果进行评估,并选择质量最高的结构)、近端策略优化(帮助模型在动态和复杂的环境中找到最优解决方案的算法)、直接偏好优化(基于用户反馈直接优化模型输出,通过调整模型的生成策略使其更符合用户偏好),全面提升Llama3推理性能。2)训练数据集质量与数量提升:Meta为Llama 3投入了超过15万亿个token数据集(7x Llama 2)进行预训练;并且为了确保数据质量,Meta开发了一系列数据过滤技术,使用了包括启发式过滤器、NSFW过滤器、语义重复数据删除方法和文本分类器来提升数据质量;此外前代Llama 2在识别高质量数据方面出奇地有效,因此也被用于为Llama 3提供训练数据。通过数据数量与质量优化,提升了Llama 3的推理性能,并减少了幻觉。Llama百亿参数“小模型”表现媲美万亿参数大模型Llama 3.3 70B较ChatGPT-4推理成本降低98%比较维度Llama 3.370BLlama 3.1405BChatGPT-4oGemini Pro 1.5公司发布时间模型参数量MMLU能力测试分数GPQA能力测试分数HumanEval能力测试分数MATH能力测试分数MetaMetaOpenAIGoogle2024.122024.72024.52024.470B86.050.588.477.0405B88.649.089.073.91T+87.547.586.076.91T+87.153.589.082.91.210.80.60.40.20推理成本(ChatGPT-4为1)1.00降低%980.170.02ChatGPT-4Llama3.1 405BLlama 3.3 70B资料来源:Meta、cnet、smatbot、SemiAnalyst、Databricks、datacamp、国海证券研究所请务必阅读报告附注中的风险提示和免责声明 32国海证券科技传媒