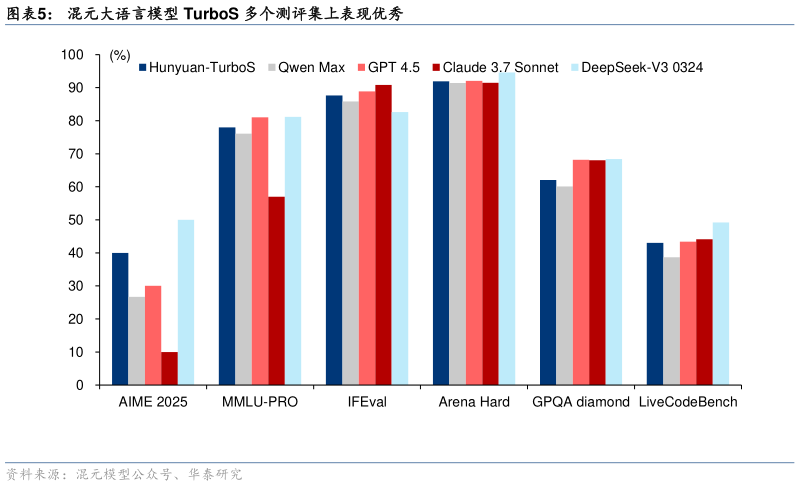
> 数据图表咨询大家混元大语言模型 TurboS 多个测评集上表现优秀
2025-6-2如果说有一些新的变化,我们认为还是要关注大厂对于模型技术路径的创新,有几个值得关注的点: 1 ) 腾 讯 于 25 年 2 月 发 布 了 混 元 大 语 言 模 型 TurboS , 是 业 界 首 个 大 规 模 部 署 的Transformer-Mamba 专家混合(MoE)模型,通过 Mamba 架构在长序列处理上的卓越效率与 Transformer 架构在上下文理解上的固有优势的有机协同,实现了性能与效率的平衡。具体架构采用了创新的“AMF”(Attention Mamba2 FFN)和“MF”(Mamba2 FFN)模块交错模式。 2)Google 的 Gemini Diffusion 可能是另一突破点。Google 于 5 月的 IO 大会上发布了Gemini Diffusion 文本扩散模型,能够通过将随机噪声转换为连贯的文本或代码来生成输出,类似图像视频生成模型的工作模式(Transformer 模型是一个词一个词输出,而 Diffusion模型一次性输出很多词再做优化,连贯性好)。Gemini Diffusion 在生成内容的速度上明显快于 Transformer 类模型,官方指出输出速度约 1479 tokenss,而一般的 Transformer 类最快也只能每秒输出数百个 token。Gemini Diffusion 在数学和代码等编辑任务中表现出色。我们认为,Gemini Diffusion 是大厂在商业化模型上首次将扩散模型用于文本生成,或是类似于 OpenAI o1 一样的重要路径转折点,实现快速地迭代解决方案,并在生成过程中进行错误校正。 3)大厂在预训练阶段参数量、数据量扩大仍有尝试。从近期的预训练阶段的更新来看,主要包括 Meta 与小米,Meta 的 Llama 4 系列模型参数进一步扩大,Llama 4 Behemoth 总参数达 2 万亿级别,是目前发布的最大参数的模型。数据量方面,小米近期发布的 MiMo 系列模型,运用了约 200B tokens 合成推理数据,进一步扩大了训练数据规模。