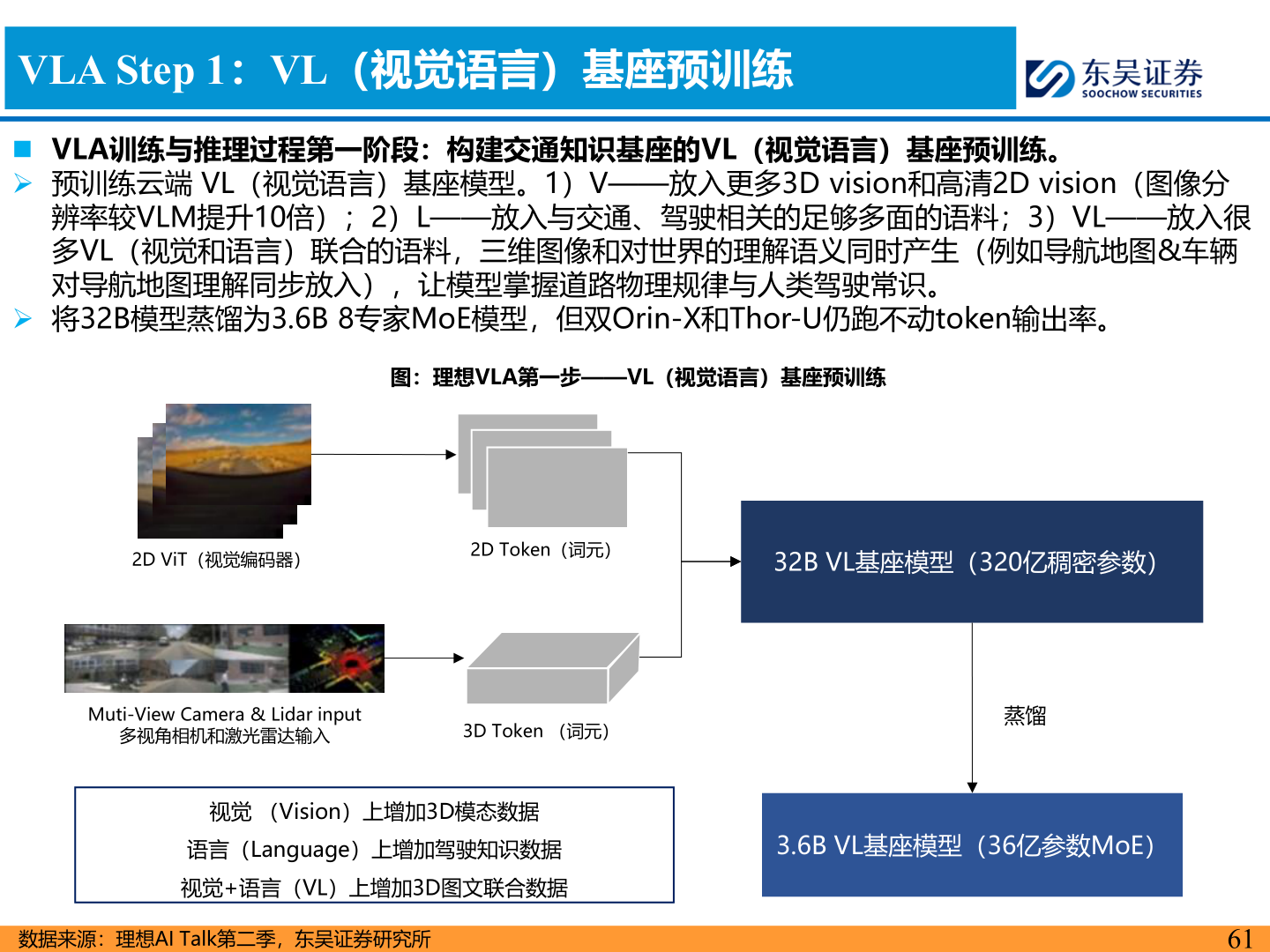
> 数据图表咨询大家VLA Step 1:VL(视觉语言)基座预训练2025-6-1VLA Step 1:VL(视觉语言)基座预训练◼ VLA训练与推理过程第一阶段:构建交通知识基座的VL(视觉语言)基座预训练。➢ 预训练云端 VL(视觉语言)基座模型。1)V——放入更多3D vision和高清2D vision(图像分辨率较VLM提升10倍);2)L——放入与交通、驾驶相关的足够多面的语料;3)VL——放入很多VL(视觉和语言)联合的语料,三维图像和对世界的理解语义同时产生(例如导航地图&车辆对导航地图理解同步放入),让模型掌握道路物理规律与人类驾驶常识。➢ 将32B模型蒸馏为3.6B 8专家MoE模型,但双Orin-X和Thor-U仍跑不动token输出率。图:理想VLA第一步——VL(视觉语言)基座预训练2D ViT(视觉编码器)2D Token(词元)32B VL基座模型(320亿稠密参数)Muti-View Camera & Lidar input多视角相机和激光雷达输入3D Token (词元)蒸馏视觉 (Vision)上增加3D模态数据语言(Language)上增加驾驶知识数据视觉+语言(VL)上增加3D图文联合数据3.6B VL基座模型(36亿参数MoE)数据来源:理想AI Talk第二季,东吴证券研究所61东吴证券综合其他