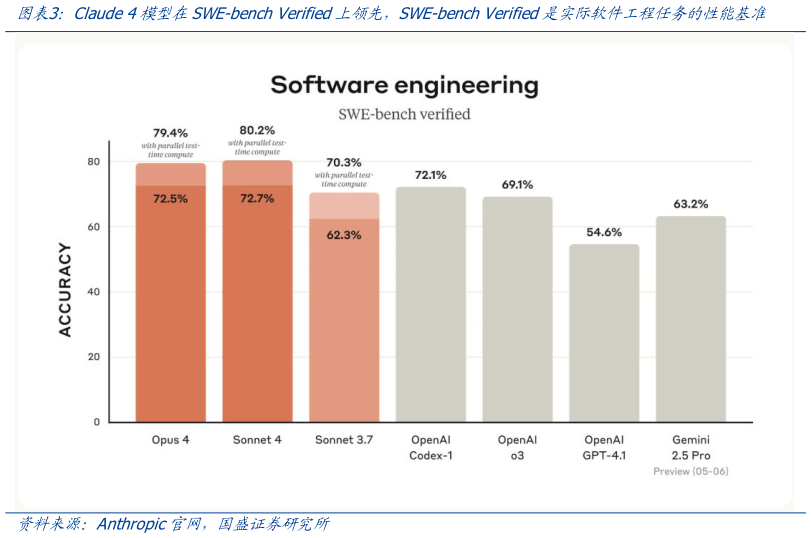
> 数据图表我想了解一下Claude 4模型在SWE-bench Verified上领先,SWE-bench Verified是实际软件工程任务的性能基准2025-6-0生成式 AI 编码为何如此有效Innolead 总结原因有三: 1、代码本质上更加结构化,为 LLM 训练提供了更受约束的数据空间。 2、代码生成系统的输出可以立即测试代码要么有效,要么无效。 3、代码质量有明确的评估基准(好、更好、最好),可以更轻松地进行微调和模型改进,包括人为微调和自动微调。 同时,GitHub 等代码社区海量的高质量代码库,也为模型训练提供了丰富的数据。 基座大模型的编程能力持续提升是 AI 编程工具落地加速的核心动力: 2025 年 5 月 23 日,Anthropic 推出 Claude 4 系列模型:Claude Opus 4 和 Claude Sonnet 4,Anthropic 称 Claude Opus 4 是世界上最好的编码模型,在复杂、长时间运行的任务和 Agent 工作流程上具有持续的性能。Claude Sonnet 4 是 Claude Sonnet 3.7 的重大升级,提供卓越的编码和推理,同时更精确地响应指示。 Claude Opus 4 是 Anthropic 最强大的模型,在 SWE-bench((72.5%)和 Terminal-bench((43.2%)上领先。它可以在需要集中精力和数千个步骤的长时间运行任务上提供持续的性能,并且能够连续工作数小时,性能大大优于所有 Sonnet 模型,并显著扩展了 AI 代理可以完成的工作。国盛证券综合其他