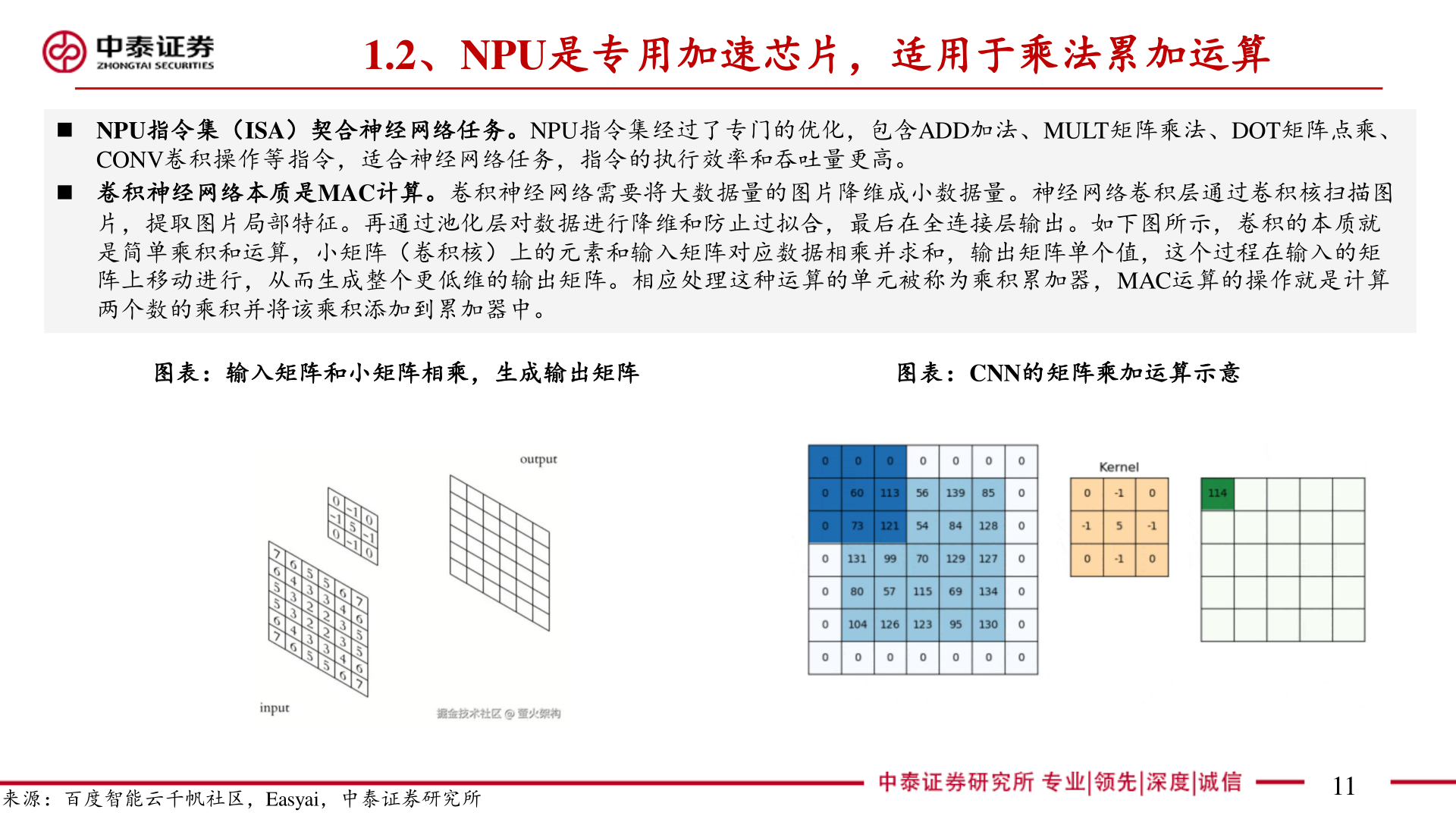
> 数据图表如何才能1.2、NPU是专用加速芯片,适用于乘法累加运算2025-4-11.2、NPU是专用加速芯片,适用于乘法累加运算◼ NPU指令集(ISA)契合神经网络任务。NPU指令集经过了专门的优化,包含ADD加法、MULT矩阵乘法、DOT矩阵点乘、CONV卷积操作等指令,适合神经网络任务,指令的执行效率和吞吐量更高。◼ 卷积神经网络本质是MAC计算。卷积神经网络需要将大数据量的图片降维成小数据量。神经网络卷积层通过卷积核扫描图片,提取图片局部特征。再通过池化层对数据进行降维和防止过拟合,最后在全连接层输出。如下图所示,卷积的本质就是简单乘积和运算,小矩阵(卷积核)上的元素和输入矩阵对应数据相乘并求和,输出矩阵单个值,这个过程在输入的矩阵上移动进行,从而生成整个更低维的输出矩阵。相应处理这种运算的单元被称为乘积累加器,MAC运算的操作就是计算两个数的乘积并将该乘积添加到累加器中。图表:输入矩阵和小矩阵相乘,生成输出矩阵图表:CNN的矩阵乘加运算示意来源:百度智能云千帆社区,Easyai,中泰证券研究所11中泰证券工业制造