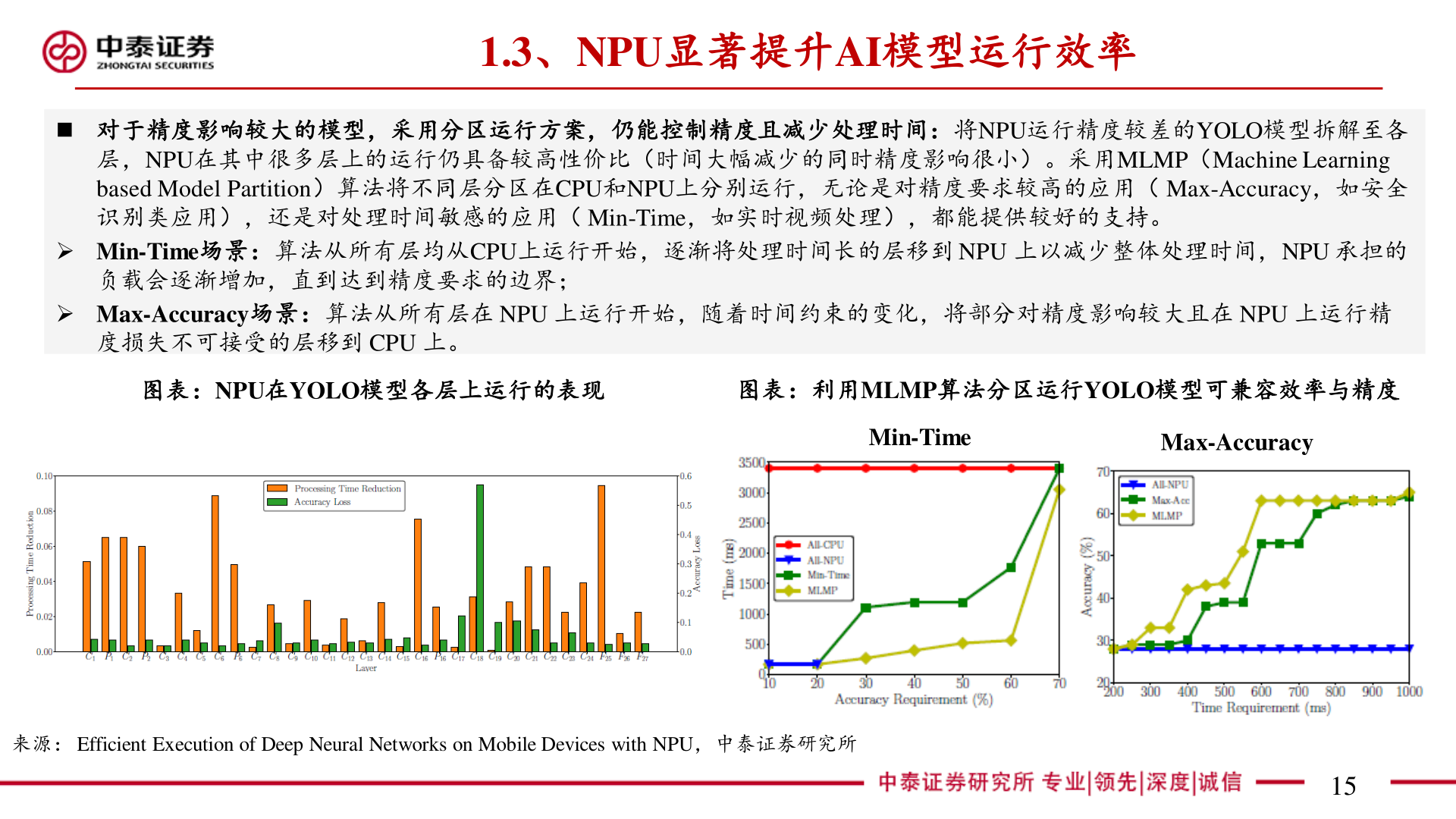
1.3、NPU显著提升AI模型运行效率◼ 对于精度影响较大的模型,采用分区运行方案,仍能控制精度且减少处理时间:将NPU运行精度较差的YOLO模型拆解至各层,NPU在其中很多层上的运行仍具备较高性价比(时间大幅减少的同时精度影响很小)。采用MLMP(Machine Learning based Model Partition)算法将不同层分区在CPU和NPU上分别运行,无论是对精度要求较高的应用( Max-Accuracy,如安全识别类应用),还是对处理时间敏感的应用( Min-Time,如实时视频处理),都能提供较好的支持。➢ Min-Time场景:算法从所有层均从CPU上运行开始,逐渐将处理时间长的层移到 NPU 上以减少整体处理时间,NPU 承担的负载会逐渐增加,直到达到精度要求的边界;➢ Max-Accuracy场景:算法从所有层在 NPU 上运行开始,随着时间约束的变化,将部分对精度影响较大且在 NPU 上运行精度损失不可接受的层移到 CPU 上。图表:NPU在YOLO模型各层上运行的表现图表:利用MLMP算法分区运行YOLO模型可兼容效率与精度Min-TimeMax-Accuracy来源: Efficient Execution of Deep Neural Networks on Mobile Devices with NPU,中泰证券研究所15