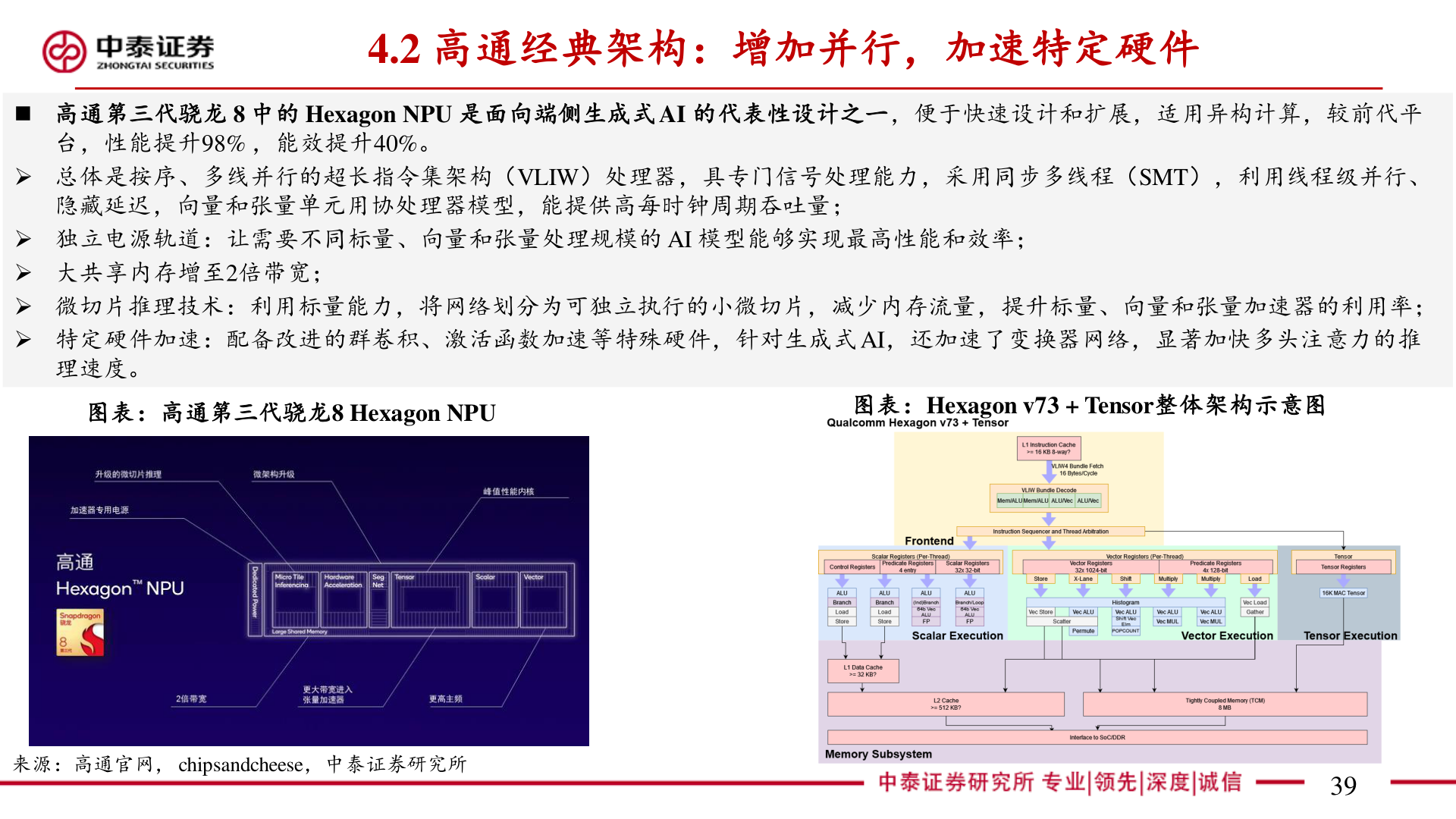
> 数据图表咨询大家4.2 高通经典架构:增加并行,加速特定硬件2025-4-14.2 高通经典架构:增加并行,加速特定硬件◼ 高通第三代骁龙 8 中的 Hexagon NPU 是面向端侧生成式 AI 的代表性设计之一,便于快速设计和扩展,适用异构计算,较前代平台,性能提升98% ,能效提升40%。➢ 总体是按序、多线并行的超长指令集架构(VLIW)处理器,具专门信号处理能力,采用同步多线程(SMT),利用线程级并行、隐藏延迟,向量和张量单元用协处理器模型,能提供高每时钟周期吞吐量;➢ 独立电源轨道:让需要不同标量、向量和张量处理规模的 AI 模型能够实现最高性能和效率;➢ 大共享内存增至2倍带宽;➢ 微切片推理技术:利用标量能力,将网络划分为可独立执行的小微切片,减少内存流量,提升标量、向量和张量加速器的利用率;➢ 特定硬件加速:配备改进的群卷积、激活函数加速等特殊硬件,针对生成式 AI,还加速了变换器网络,显著加快多头注意力的推理速度。图表:高通第三代骁龙8 Hexagon NPU图表:Hexagon v73 + Tensor整体架构示意图来源:高通官网, chipsandcheese,中泰证券研究所39中泰证券工业制造