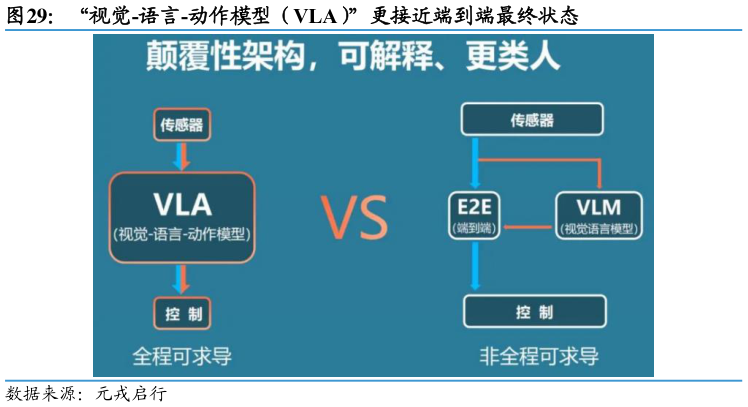
> 数据图表如何了解“视觉-语言-动作模型(VLA)”更接近端到端最终状态2025-8-22.2.2. VLA 一体化模型直接端到端输出行为,复杂环境适应能力提高 在上述需求、大模型技术、芯片算力的共同催化下,一体化大模型呼声愈增,VLA应运而生。“视觉-语言-动作模型(VLA)”最早于 2023 年 7 月由 Google DeepMind提出用于机器人领域,在 VLM 的基础上发展而来,被视为端到端大模型 2.0。VLA大模型以大语言模型为基础,在接收摄像头的原始数据和语言指令后,可直接输出控制信号,完成各种复杂的操作。VLA 相当于端到端VLM 双系统的集合版本:在双系统中,VLM 着重于图像和场景的理解,为智驾决策规划提供输入,最终依然需要依靠端到端模型输出对车辆的控制,而 VLA 则将端到端与多模态大模型更彻底地融合,能够根据感知直接生成车辆的运动规划和决策,更接近“图像输入、控制输出”的端到端最终状态。国泰海通综合其他