> 数据图表想关注一下VLA 架构包含:空间数据建构、基座模型推理、动作生成三个主要部分
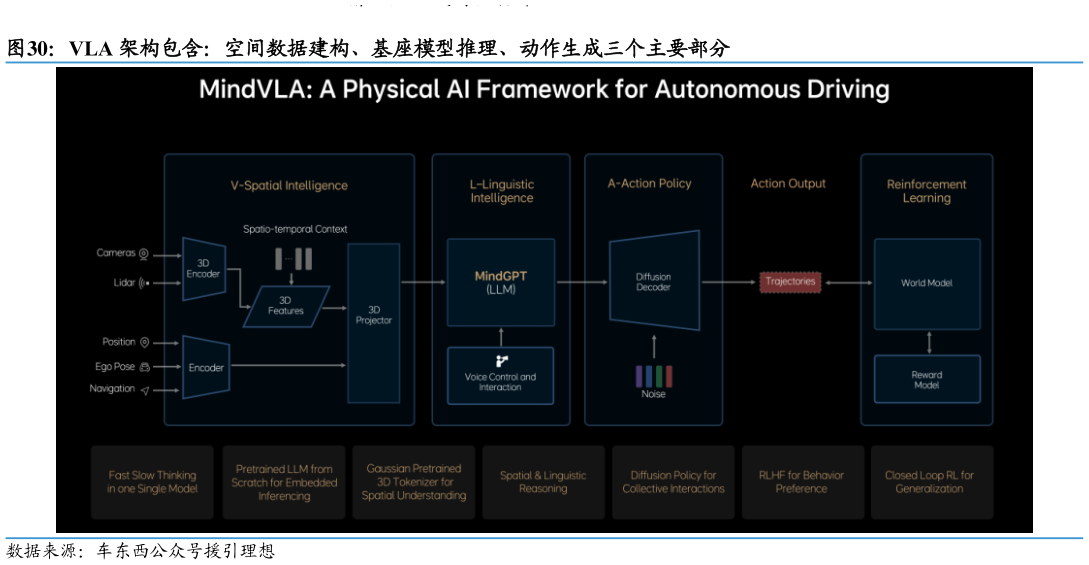
2025-8-2以理想于 2025 年 3 月提出的 MindVLA 智驾方案为例,VLA 架构包含:空间数据建构、基座模型推理、动作生成三个主要部分。 V(Spatial-Intelligence)实现 3D 空间建构,理想在 BEVOCC 的基础上采用 3D Gaussian 作为中间表征技术,进行 3D 高斯场景重建,能够提供多粒度、多尺度、更丰富的 3D 几何尺度表达能力并通过图片 RGB 进行自监督训练,更好的输出未来帧高斯建模场景。 L(Lingustic Intelligence)重新设计和训练 LLM 基座模型,模型架构上受到DeepSeek 启发采用 MoE 架构实现多任务并行处理,结合稀疏注意力(Sparse Attention)优化计算效率,在实现模型容量扩容的同时不会大幅度增加推理负担。推理能力上,锻炼模型学习人类的快思考慢思考过程,快思考采用并行解码方式直接输出 Action Token,慢思考则同时输出思维链 CoTAction Token。 A(Action Policy)输出 Action,利用扩散模型(Diffusion Model)进行预测,接入上游输出的 Action Token 解码成优化的轨迹,预测未来特定时长下的场景发生情况,生成驾驶动作。