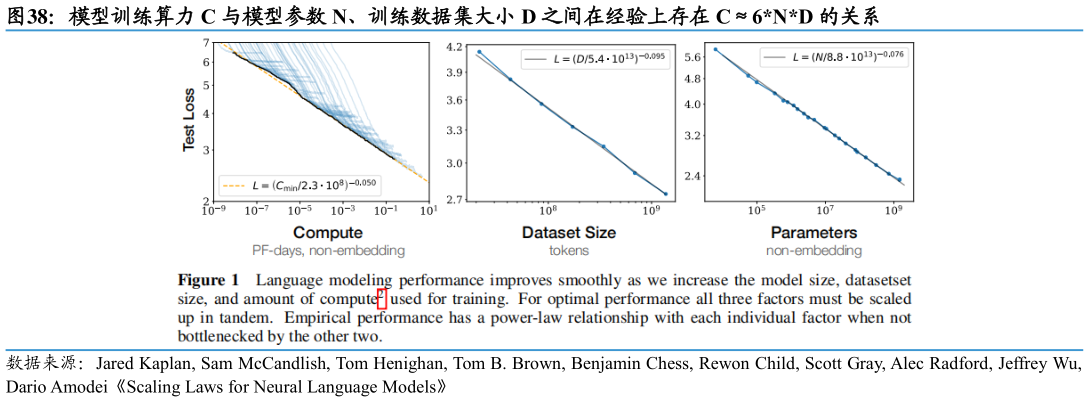
> 数据图表各位网友请教一下模型训练算力 C 与模型参数 N、训练数据集大小 D 之间在经验上存在 C6ND 的关系
2025-8-2另一方面,从 L2-L4 升级过程中模型参数将倍数级扩大,安全性与复杂性的平衡需要海量训练数据支撑,要求车企训练算力储备持续扩容。根据地平线数据,L2级智能驾驶的车端算力需求为 100TOPS,L3 级智能驾驶为 500-1000TOPS,L4级智能驾驶为 2000TOPS 以上,L5 级则需要 5000TOPS 以上。车端算力最直观体现大模型上车的计算资源需求,其 10 倍数级的提升侧面反映智能驾驶大模型参数的迅速增长。数据方面,L2 为辅助驾驶,L4 为全自动驾驶,要求对于现实世界中的复杂场景具有自主解决的能力,因此更高的可靠性意味着需要更多数据来验证和优化系统,减少出错的可能性。根据德勤数据报告显示,预计 2025 年 L3 智能驾驶商业落地,单个 L3 算法模型具有十亿级数据标注需求,智能驾驶数据服务市场规模将达到 51.6 亿元。2030 后 L4 智能驾驶或逐步落地,单个 L4 模型标注需求将增长至百亿至千亿级,数据需求或于 2027 年后逐步释放,数据服务市场规模将增长至 74.9 亿元。训练算力方面,根据 OpenAI 的经验公式 C6ND(C 为训练一个 Transformer 模型所需的算力,N 为模型参数,D 为训练数据集的大小),可以理解为训练算力需求模型参数量数据集 token 数系数 k。因此在模型参数与数据同时显著增长的情况下,对车企训练算力的储备需求越来越高,模型训练的资金投入也倍数级增长。