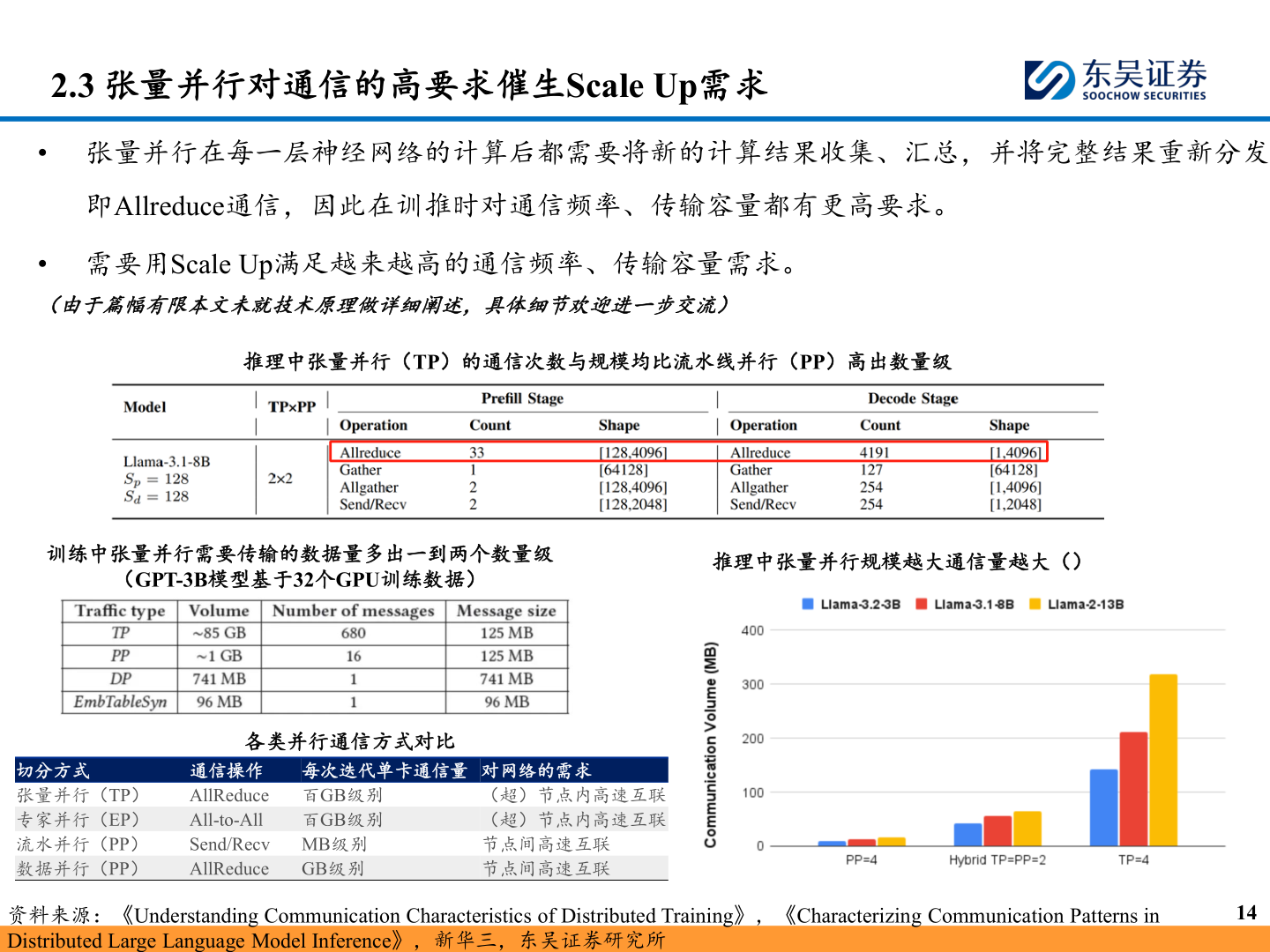
2.3 张量并行对通信的高要求催生Scale Up需求• 张量并行在每一层神经网络的计算后都需要将新的计算结果收集、汇总,并将完整结果重新分发,即Allreduce通信,因此在训推时对通信频率、传输容量都有更高要求。• 需要用Scale Up满足越来越高的通信频率、传输容量需求。(由于篇幅有限本文未就技术原理做详细阐述,具体细节欢迎进一步交流)推理中张量并行(TP)的通信次数与规模均比流水线并行(PP)高出数量级训练中张量并行需要传输的数据量多出一到两个数量级(GPT-3B模型基于32个GPU训练数据)推理中张量并行规模越大通信量越大()各类并行通信方式对比切分方式张量并行(TP)专家并行(EP)流水并行(PP)数据并行(PP)通信操作AllReduce 百GB级别百GB级别All-to-AllSend/Recv MB级别GB级别AllReduce每次迭代单卡通信量 对网络的需求(超)节点内高速互联(超)节点内高速互联节点间高速互联节点间高速互联资料来源:《Understanding Communication Characteristics of Distributed Training》,《Characterizing Communication Patterns in Distributed Large Language Model Inference》,新华三,东吴证券研究所14