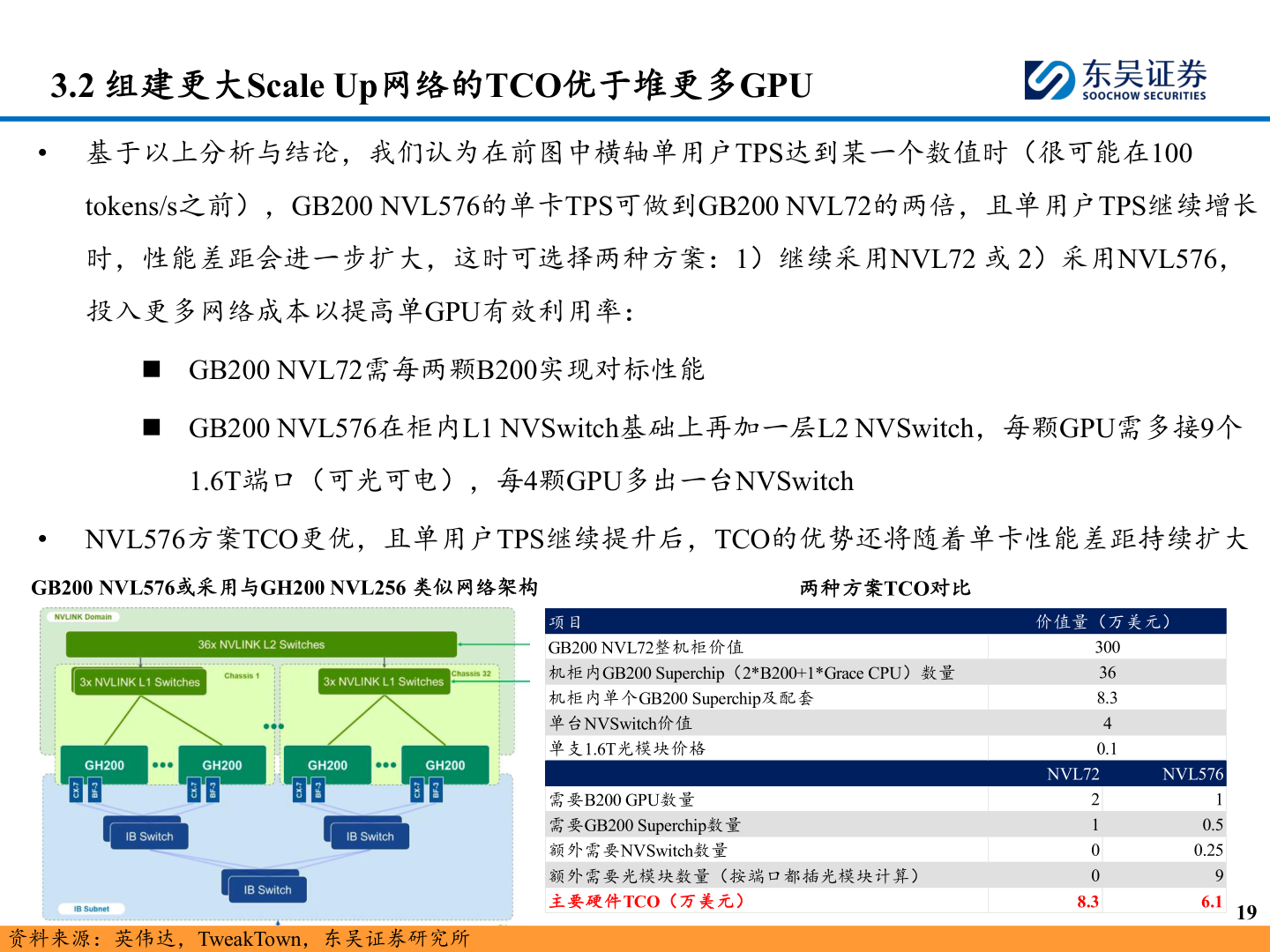
> 数据图表谁能回答3.2 组建更大Scale Up网络的TCO优于堆更多GPU2025-8-23.2 组建更大Scale Up网络的TCO优于堆更多GPU• 基于以上分析与结论,我们认为在前图中横轴单用户TPS达到某一个数值时(很可能在100tokens/s之前),GB200 NVL576的单卡TPS可做到GB200 NVL72的两倍,且单用户TPS继续增长时,性能差距会进一步扩大,这时可选择两种方案:1)继续采用NVL72 或 2)采用NVL576,投入更多网络成本以提高单GPU有效利用率:◼ GB200 NVL72需每两颗B200实现对标性能◼ GB200 NVL576在柜内L1 NVSwitch基础上再加一层L2 NVSwitch,每颗GPU需多接9个1.6T端口(可光可电),每4颗GPU多出一台NVSwitch• NVL576方案TCO更优,且单用户TPS继续提升后,TCO的优势还将随着单卡性能差距持续扩大GB200 NVL576或采用与GH200 NVL256 类似网络架构两种方案TCO对比资料来源:英伟达,TweakTown,东吴证券研究所19项目GB200 NVL72整机柜价值机柜内GB200 Superchip(2*B200+1*Grace CPU)数量机柜内单个GB200 Superchip及配套单台NVSwitch价值单支1.6T光模块价格需要B200 GPU数量需要GB200 Superchip数量额外需要NVSwitch数量额外需要光模块数量(按端口都插光模块计算)主要硬件TCO(万美元)价值量(万美元)300368.340.1NVL72NVL57621008.310.50.2596.1东吴证券综合其他