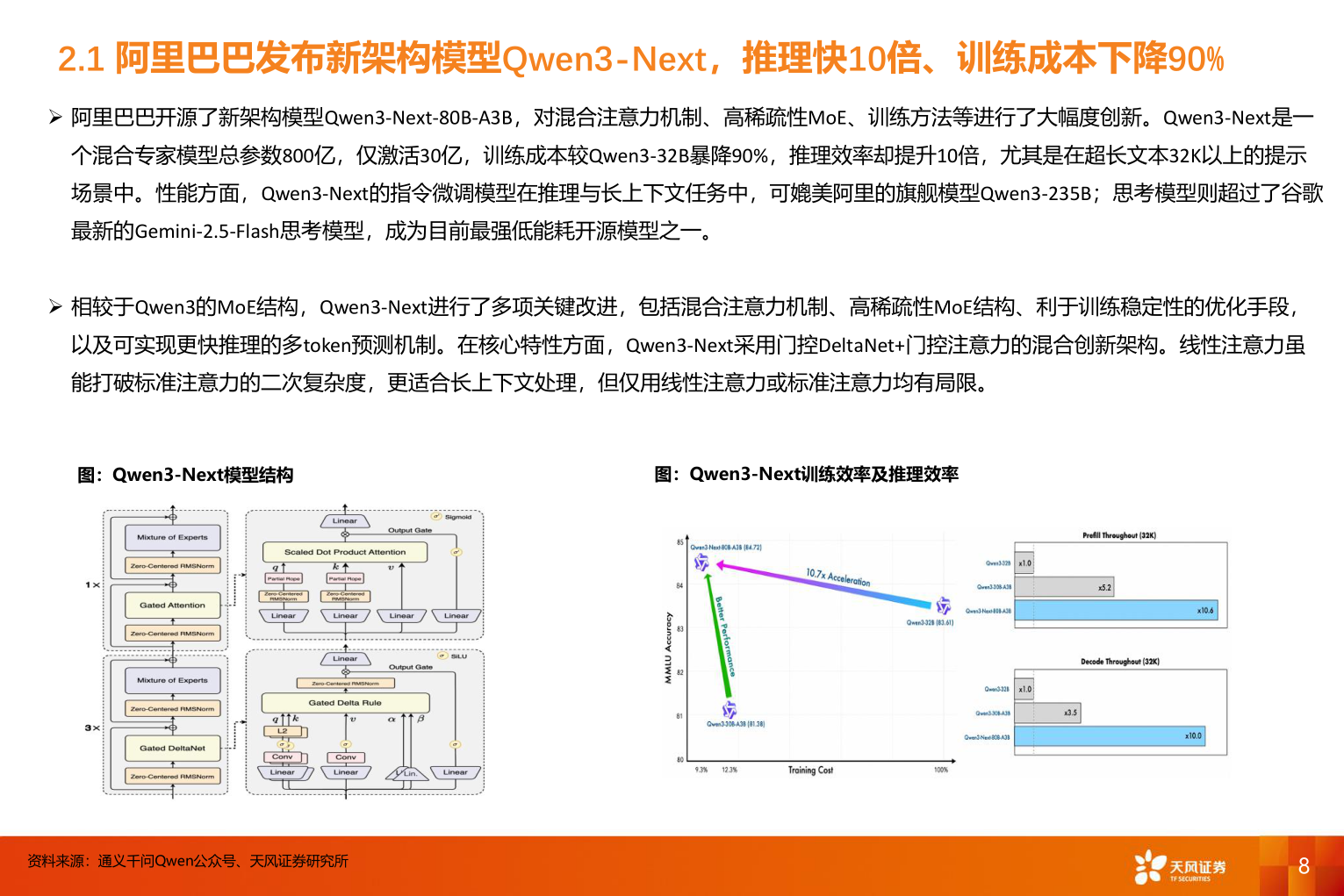
> 数据图表各位网友请教一下2.1 阿里巴巴发布新架构模型Qwen3-Next,推理快10倍、训练成本下降90%2025-9-12.1 阿里巴巴发布新架构模型Qwen3-Next,推理快10倍、训练成本下降90%➢ 阿里巴巴开源了新架构模型Qwen3-Next-80B-A3B,对混合注意力机制、高稀疏性MoE、训练方法等进行了大幅度创新。Qwen3-Next是一个混合专家模型总参数800亿,仅激活30亿,训练成本较Qwen3-32B暴降90%,推理效率却提升10倍,尤其是在超长文本32K以上的提示场景中。性能方面,Qwen3-Next的指令微调模型在推理与长上下文任务中,可媲美阿里的旗舰模型Qwen3-235B;思考模型则超过了谷歌最新的Gemini-2.5-Flash思考模型,成为目前最强低能耗开源模型之一。➢ 相较于Qwen3的MoE结构,Qwen3-Next进行了多项关键改进,包括混合注意力机制、高稀疏性MoE结构、利于训练稳定性的优化手段,以及可实现更快推理的多token预测机制。在核心特性方面,Qwen3-Next采用门控DeltaNet+门控注意力的混合创新架构。线性注意力虽能打破标准注意力的二次复杂度,更适合长上下文处理,但仅用线性注意力或标准注意力均有局限。图:Qwen3-Next模型结构图:Qwen3-Next训练效率及推理效率资料来源:通义千问Qwen公众号、天风证券研究所8天风证券综合其他