> 数据图表各位网友请教一下通过解耦上下文处理和生成阶段,最大化输出效率
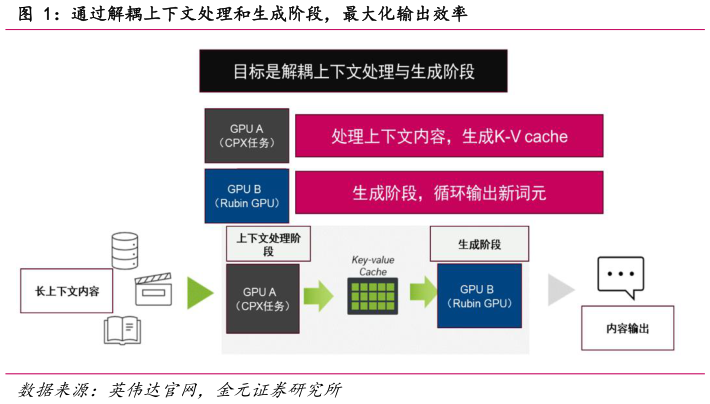
2025-9-12025 年 9 月 9 日,英伟达宣布推出 Rubin CPX GPU,旨在通过增强推理阶段的长上下文处理性能,提升首 Token 速率,补充现有基础设施。同时在上下文感知推理部署中提供可扩展的效率并最大限度地提高投资回报率。Rubin CPX 采用 Rubin 架构构建,主要用于计算密集型上下文阶段的性能提升。算力角度,NVFP4 精度下,CPX 算力水平达到 30petaFlops,具有 128G GDDR7 内存。 为何不使用 HBM针对“计算墙”和“内存墙”的定点优化,且能够有效放大投资回报率。Rubin CPX 与 NVIDIA Vera CPU 和 Rubin GPU 可以协同工作,进行生成阶段处理,为长上下文用例形成完整的高性能分解服务解决方案。推理需求市场远大于训练市场,现代模型的发展对算力资源的要求是能够处理推理阶段的长上下文能力以及长记忆,使模型能够具备处理多场景、复杂任务的能力。不同于训练任务的前后向传播对参数、梯度等进行计算、更新,推理主要由两个不同的阶段组成,一个是上下文处理阶段,另一个是生成阶段。 上下文处理阶段是计算密集型任务(基于屋顶檐模型,主要为“计算墙”瓶颈),分为预填充(prefill)和预处理阶段。但是只需要一次操作,处理速度取决于输入提示(prompts)的长度。模型会并行地处理整个输入序列,因为Transformer 的自注意力机制允许模型同时看到并计算所有输入词元之间的关系。整个输入序列计算并缓存每个层的 Key 和 Value 矩阵。这一步至关重要,是为后续生成阶段做的准备工作。