> 数据图表如何了解高速率铜互连瓶颈约束 Scale-up 上限
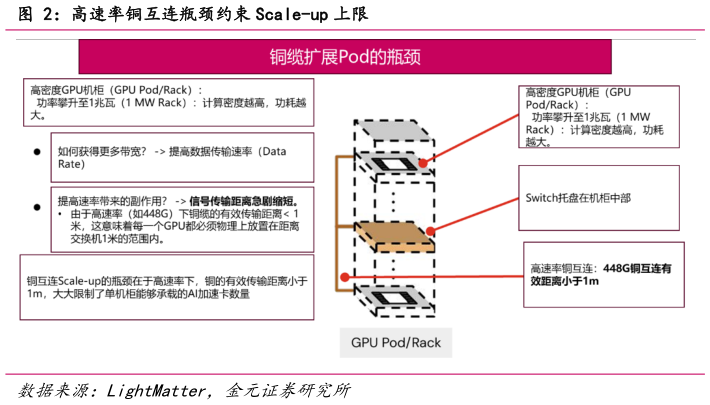
2025-9-1Scale-up单机柜扩展,以 NVL72 为例,单机柜整合 18 个计算托盘,9 个交换托盘,单个计算托盘集成两张 GB200300,每个 GB200300 上有 2个 B200、B300 计算芯片:相当于将多张卡整合在一个计算节点,整个机柜如同整张“GPU”,共享内存。机柜内部的多张算力芯片通过 switch芯片实现完全互连(即单卡与单卡之间直接交互)。Scale-Up 侧重片内机内互连,需要极高带宽和低延迟的连接。Scale-up 的核心是在于单个机柜的高密度 GPU,为应对 AI 训练和大模型推理等计算密集型任务,数据中心采用高度集成化的设计。将数百甚至上千个 GPU 集中在一个机柜或一组机柜(称为一个 Pod)中,可以让它们协同工作,像一台巨型计算机一样解决问题。 Scale-up 面临的问题在于两个方面:1、功率极具攀升,计算密度越高,功耗越大。2、带宽、速率与传输距离的矛盾。提高带宽的方式是提高数据传输速率,当前机柜内主要通过铜互连(NVLink 为例)实现,铜的瓶颈在于由于高速率(如 448G)下铜缆的有效传输距离 1 米,这意味着每一个 GPU 都必须物理上放置在距离交换机 1 米的范围内。一个机柜的物理空间是有限的(通常是标准机架尺寸)。在交换机周围 1 米的“球体”空间内,能放入多少 GPU 加速卡ASIC 和其散热装置是有一个物理上限