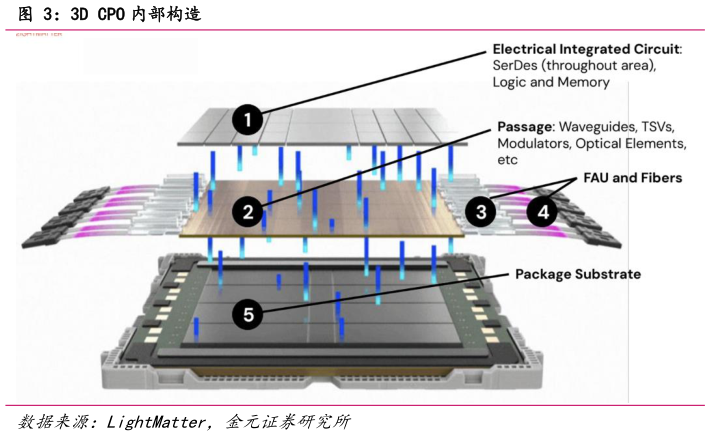
> 数据图表如何了解3D CPO 内部构造
2025-9-1Scale-out(集群扩展): 通过增加更多服务器节点并通过高速网络互联,构建更大的单数据中心 AI 集群(通常在同一机房园区内)。典型如英伟达的 DGX SuperPOD(数百上千 GPU 通过 InfiniBand 或以太网交换机互连成一个训练集群)。 Scale-Out 关注机架间集群内网络,要求高端口数量、高带宽密度的交换结构,以及微秒级低延迟通信。在此层面,光纤连接早已成为主流,例如 400 Gbps、800 Gbps、1.6Tbps 光模块通过 TOP(Top-of-Rack)交换机连接各服务器。随着 AI 集群规模从数十节点扩大到上千甚至上万节点,传统电背板和可插拔光模块面临严峻挑战,需要处理成百上千条高速链路,交换芯片容量突破 50 Tbps、 100 Tbps,光模块功耗和成本也随端口数剧增。共封装光学 CPO 由此进入集群网络层面的视野,通过将光引擎直接与交换 ASIC 集成,可以大幅提升交换机的总带宽和端口密度,并降低每比特功耗。在 GTC 大会上,黄仁勋曾举例称,由 25 万颗 GPU 组成的AI 网络中,如果每 GPU 需配 6 个光模块连接交换机,那么光模块本身的费用将为每 GPU 增加约 6000 美元功耗增加 180 W整个系统将承受难以持续的成本和能耗。CPO 正是为缓解此问题而生,通过取消箱体前面板大量可插拔模块,改由低功耗的封装内光引擎直接输出光纤,可带来量级上的能效改进。另一方面,与 Scale-up 的痛点一致,随着单芯片总线带宽飙升至 50 Tbps、100 Tbps 甚至更高,传统 PCB 走线无法在合理功耗下支持 112 Gbaud、224 Gbaud 等速率信号传输,因此当交换 ASIC 走向102.4 Tbps 及 400 Glane 时代,CPO 或将成为唯一可行方案。