> 数据图表怎样理解传统算力测试性能结果对比
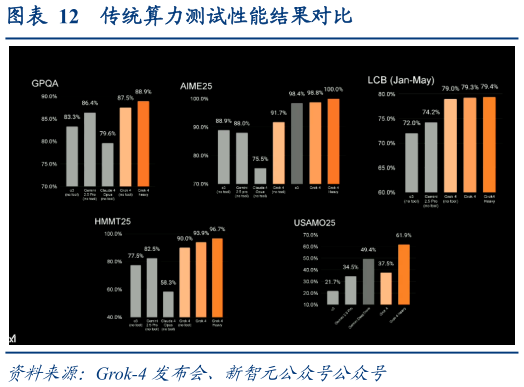
2025-9-2Grok-4 在复杂知识领域以及相关测试中表现优异。马斯克在发布会上宣称 Grok-4 在理工、编程等高难度学科领域已达到博士研究水平。Grok-4 由 xAI 的 Colossus 超级计算机训练,在 API 模式下支持 256,000 tokens 的超大上下文窗口,远超前代 Grok-3 的处理能力。自 Grok-2 至 Grok-4,计算资源投入总共增加了一百倍。xAI 推出普通单智能体“Grok-4”与会员版多智能体 “Grok-4 Heavy” 双版本。会员版支持多个智能体并行工作,通过小组协作思考,选取最优解决方案。在性能测试上, xAI 采用人类最后一场闭卷考试(Human-Level Examination, HLE)基准对 Grok-4 进行评估。HLE 基准测试由全球多领域权威专家联合制定,涵盖数学、生物、计算机等学科的 2500 个高阶专业问题,对标博士级科研难度,在业界内是评估模型在跨学科推理、复杂系统分析能力的权威测试。Grok-4 以 44.4%的准确率,刷新了历史得分记录Grok-4 在国际数学竞赛 AIME 2024、SAT 以及美国研究生入学考试 GRE 等传统大模型测试中取得了高分。目前两款模型在复杂知识表征、跨域推理及高阶认知测试得分优于 OpenAI o3、Gemini 2.5 Pro 以及 Claude 4 等当前的业内大模型。