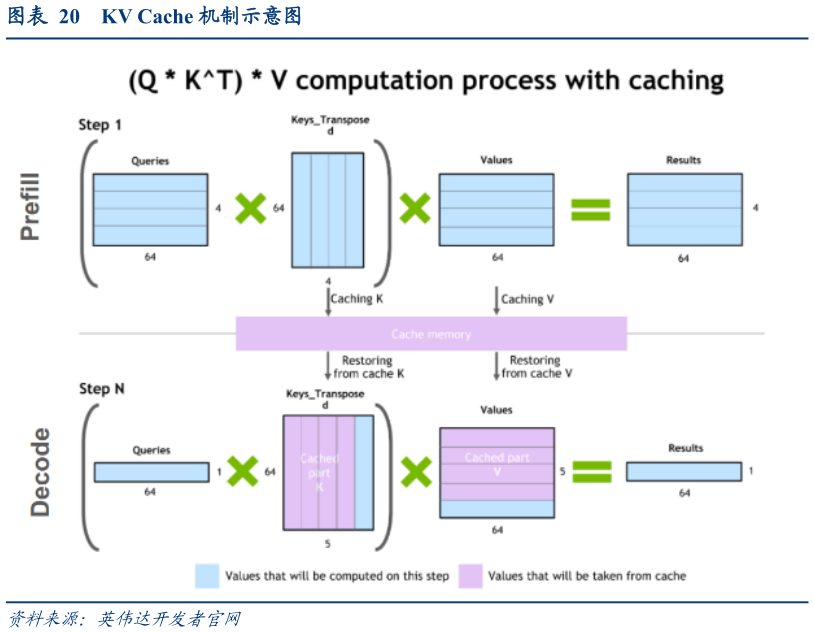
> 数据图表一起讨论下KV Cache 机制示意图
2025-11-32、KV Cache 容量增长超出 HBM 承载上限,或将卸载至 DRAM 和 SSD历史 token 计算结果缓存可显著提高效率,KV Cache 技术应运而生。在大模型领域,随着模型参数规模的扩大和上下文长度增加,算力消耗显著增长。以多轮对话场景为例,随着对话轮数增加,历史 token 重算占比持续增长。因此,构建高效的历史 token 计算结果缓存机制,理论上可以实现对重复计算过程的智能规避,从而显著提升计算资源的利用效率,KV Cache 技术应运而生。为了避免在每个时间步为所有令牌重新计算所有这些张量,可以将它们缓存在 GPU 内存中。每次迭代,当计算新元素时,它们都会简单地添加到正在运行的缓存中,以便在下一次迭代中使用。