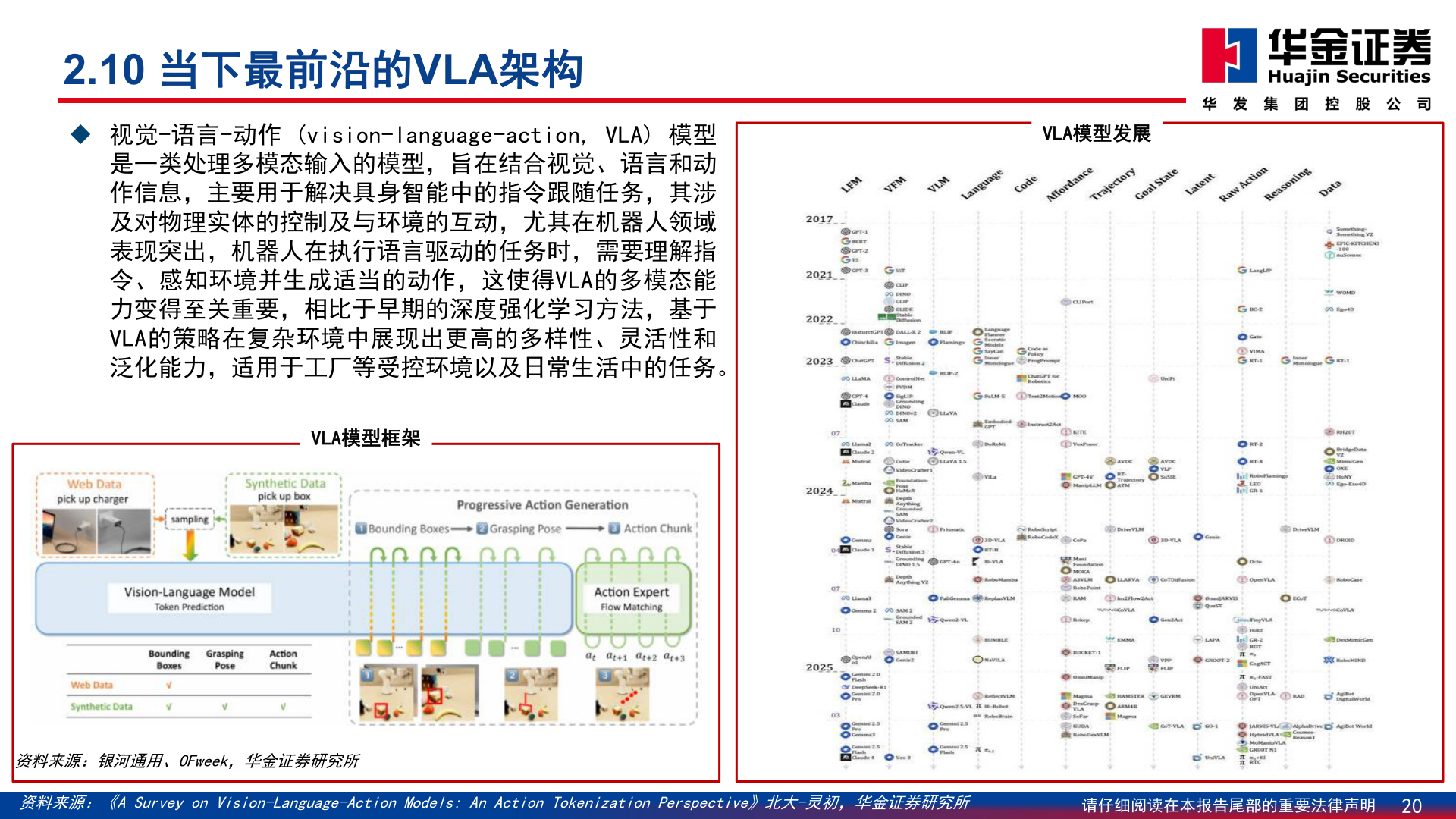
> 数据图表怎样理解2.10 当下最前沿的VLA架构2025-8-12.10 当下最前沿的VLA架构u 视觉-语言-动作 (vision-language-action, VLA) 模型是一类处理多模态输入的模型,旨在结合视觉、语言和动作信息,主要用于解决具身智能中的指令跟随任务,其涉及对物理实体的控制及与环境的互动,尤其在机器人领域表现突出,机器人在执行语言驱动的任务时,需要理解指令、感知环境并生成适当的动作,这使得VLA的多模态能力变得至关重要,相比于早期的深度强化学习方法,基于VLA的策略在复杂环境中展现出更高的多样性、灵活性和泛化能力,适用于工厂等受控环境以及日常生活中的任务。VLA模型框架VLA模型发展资料来源:银河通用、OFweek,华金证券研究所资料来源:《A Survey on Vision-Language-Action Models: An Action Tokenization Perspective》北大-灵初,华金证券研究所请仔细阅读在本报告尾部的重要法律声明20华金证券工业制造