> 数据图表如何看待大语言模型参数规模的爆炸式增长
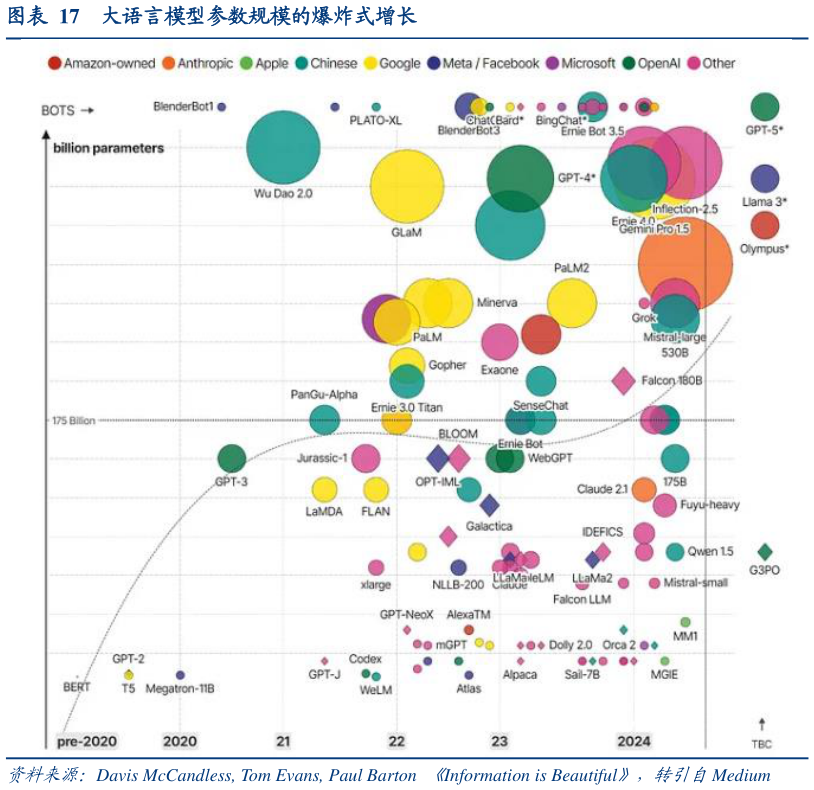
2025-8-1AI 大模型与高性能计算的崛起,使服务器对带宽与存储提出极致需求。随着 ChatGPT 等生成式 AI 加速落地,大模型训练参数规模迅速从数十亿级跃升至万亿级。据华尔街见闻援引 SemiAnalysis 数据,GPT-4 训练所用 token 规模达到 13 万亿,单次训练成本高达6300 万美元。如此大规模模型训练涉及 TB 级数据并行处理,服务器对算力、内存带宽、延迟和功耗的要求大幅提升。此外,AI 推理环节同样面临高数据吞吐、低延迟的严苛考验。传统的服务器架构采用 CPUGPU 配合 DDR 内存的方案,在带宽密度、数据吞吐能力上已无法支撑大规模 AI 场景的极致需求,迫切需要更高性能、更低延迟的存储解决方案。