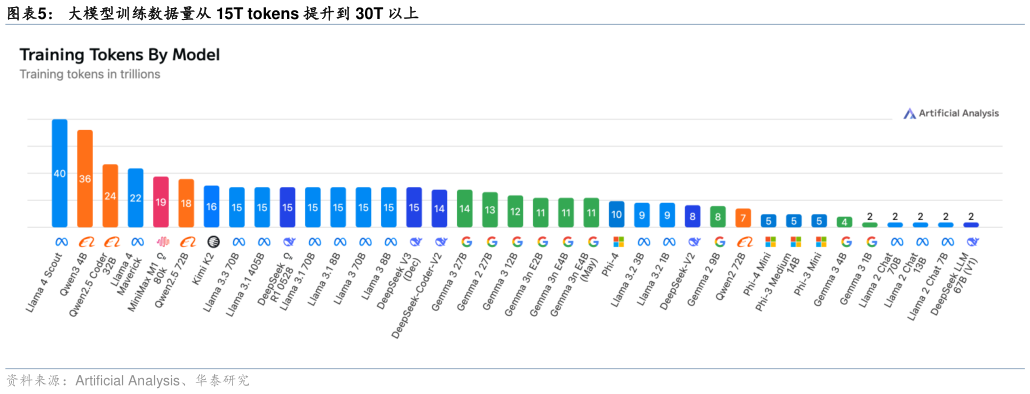
> 数据图表咨询下各位大模型训练数据量从 15T tokens 提升到 30T 以上2025-12-5Scaling Law 要求数据和参数量同比例增长,头部厂商通过新增标注和合成数据等方法持续扩容训练数据。2022 年 3 月,DeepMind 提出 Chinchilla Scaling Laws,指出为了使模型达到最佳性能,模型参数量应与训练集的大小成等比例扩张,并给出算力、模型和训练Token 间的比例关系。我们观察到新近模型的训练 tokens 继续上行:例如阿里 Qwen 系列由 18 万亿提升至 36 万亿,Meta 在训练 Llama 4 Scout 时引入部分社交数据,使总体训练数据约达 40 万亿。我们认为,随“垂类”数据与新标注数据的不断累积,训练 tokens 仍将增加,且从模型泛化性和性能表现来看,OpenAI、Google 等头部模型的训练规模或高于公开口径。华泰证券综合其他