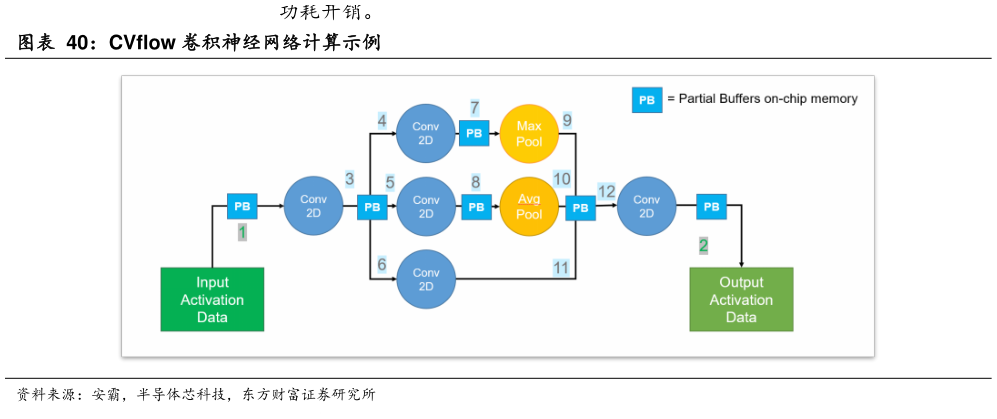
> 数据图表如何了解CVflow 卷积神经网络计算示例2026-1-5轻量级行泊一体域控加速向全时运行单 SoC 方案集中,架构效率优势逐步显现。与传统缓存系统不同,CVflow 架构通过创新性的片上内存组织方式,将 On-chip Memory 划分为多个不同大小的内存块,即 Partial Buffers(PB),用于存储计算过程中的中间结果,从而显著减少对外部 DRAM 的访问次数。在轻量级行泊一体域控向单 SoC 全时运行方案集中的技术趋势下,该架构在算力效率与系统能效层面具备较强适配性。具体来看,PB 结构相较传统缓存设计更为简洁,有助于节省芯片面积并降低制造成本与功耗同时,CVflow 为 PB配置独立 DMA(Direct Memory Access)通道,实现 DRAM 与 PB 之间的大块数据高效传输,避免多次小数据搬运带来的带宽瓶颈,并减少数据在内存与向量处理器(NVP)之间的搬运次数,从而降低访存延迟与系统开销。此外,PB 在 CVflow 内部以环形结构组织,使数据预加载可与计算单元并行进行,硬东方财富证券综合其他