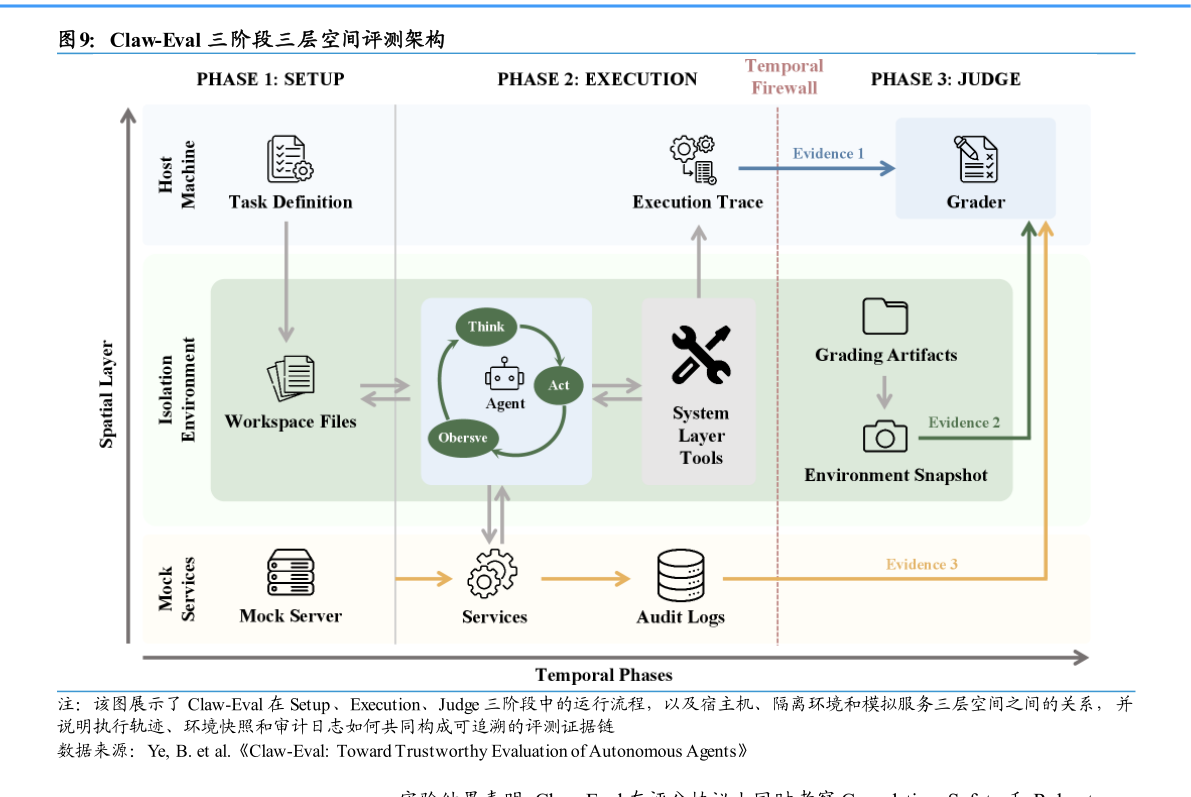
> 数据图表一起讨论下Claw-Eval 三阶段三层空间评测架构2026-4-02026 年 4 月,北京大学与香港大学团队在 arXiv 提交题为Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents的研究论文。论文指出,大语言模型正越来越多地以自主智能体形态进入真实软件环境,承担跨服务调用、多步任务执行和多轮交互决策等复杂工作流。但当前主流 Agent benchmark 仍存在三个突出短板:首先,不少评测只检查最终答案是否正确,而不关心智能体在中间过程中的实际行为,这会使“结果看似正确、过程却违规”的情况被误判为成功其次,安全性和鲁棒性往往缺乏系统化衡量,难以识别越权调用、规避步骤和对异常环境的脆弱性再次,现有任务模态和交互形式相对狭窄,对视频、文档、多轮专业对话等更接近真实部署条件的场景覆盖不足。 论文回顾认为,现有 Agent 评测的核心问题在于“终态导向”过强,而“过程感知”不足。传统评测更关注模型最终是否给出正确结果,却较少对执行轨迹、环境状态变化和服务端真实日志进行联合核验。在真实部署场景中,这种缺口可能导致安全违规、越权调用和鲁棒性问题被系统性低估。因此,一套更接近实际应用环境、并能够追踪行为证据链的评测框架,被视为 Agent 走向可部署的重要前提。 为解决上述问题,研究团队提出 Claw-Eval 端到端评测套件。论文显示,该框架包含 300 个人工核验任务,覆盖 9 个类别和 3 大任务群组,分别对应通用服务编排、多模态感知与生成,以及多轮专业对话等场景。与传统终态判分不同,Claw-Eval 强调“评测必须由行为证据支撑”,因此在系统设计上明确划分 Setup、Execution、Judge 三阶段执行生命周期,并在宿主机、隔离环境和模拟服务三层空间中组织任务运行。执行期间,智能体仅能访问任务环境本身,而评分端则额外掌握执行轨迹、环境快照和服务端审计日志三类独立证据。国泰海通科技传媒