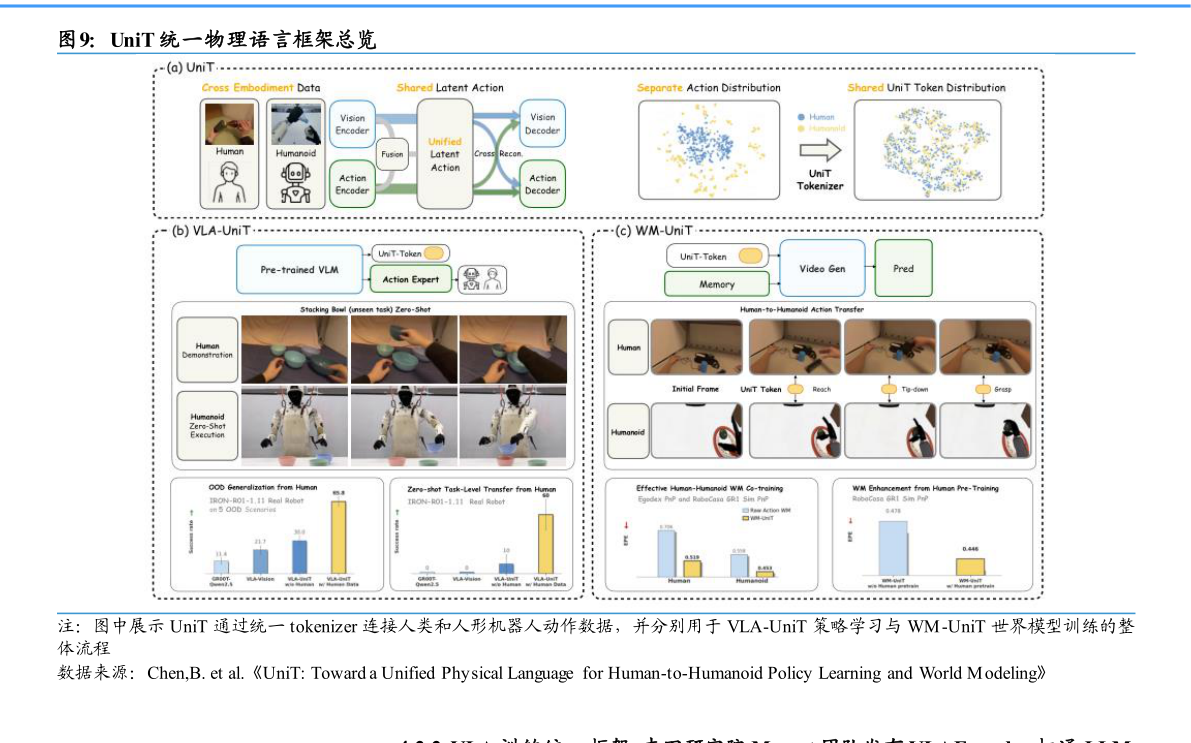
4.2. 人工智能与物理 AI 板块动态 4.2.1. 人形机器人统一物理语言:小鹏机器人 Chen 团队提出 UniT 实现人类到人形策略与世界模型迁移 2026 年 4 月,小鹏机器人、清华大学、香港大学等机构组成的 Boyu Chen 团队在arXiv 发布题为UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling的论文。论文提出 UniT 框架,即 Unified Latent Action Tokenizer via Visual Anchoring,尝试在人类动作数据和人形机器人动作空间之间建立统一潜在动作表示,用于策略学习和动作条件世界模型。 人形机器人基础模型的扩展受制于高质量机器人数据稀缺。与之相比,低成本采集的人类第一视角或动作数据规模更大,并包含丰富的物理交互先验,但人类与机器人在自由度、运动学结构和控制接口上存在明显差异。传统动作重定向依赖针对具体机器人和任务的运动学求解,难以规模化。论文认为,若要利用大规模人类数据训练人形机器人,需要一种跨具身形态的“物理语言”,把不同动作映射到共享意图空间。 UniT 的核心假设是,尽管人类与人形机器人的关节结构不同,物理意图产生的视觉后果具有一致性。基于这一点,框架采用三分支交叉重构机制,同时编码连续视觉帧、动作片段以及视觉-动作融合特征,并通过共享离散潜在空间提取与具身形态无关的物理意图。动作分支需要重构视觉转移,以避免只记忆特定形态的关节信号视觉分支需要重构动作,以过滤纹理、光照和背景等低层视觉干扰。 在策略学习方向,研究团队将 UniT token 接入视觉-语言-动作模型,形成 VLA-UniT。模型不直接在跨形态原始动作空间回归,而是预测共享潜在动作 token,再通过轻量化 flow head 生成面向特定机器人执行的控制。论文在 RoboCasa GR1 仿真和 IRON-R01-1.11 真实人形机器人上验证该方法,报告 VLA-UniT 在 RoboCas a GR1 全量数据设置下达到 66.7%的总体成功率,优于文中比较的基线在 10%训练数据条件下达到 45.5%成功率,体现出数据效率提升。 在世界模型方向,研究团队提出 WM-UniT,将 UniT token 作为动作条件而非直接使用原始动作。论文称,在 EgoDex 人类数据与 RoboCasa-GR1 机器人数据联合训练下,UniT 能够改善人类与人形机器人动作条件视频生成的一致性,并在人类到机器人条件生成场景中提高可控性。t-SNE 可视化显示,人类与人形机器人样本在 UniT 表示中更趋向共享流形,为跨具身迁移提供了结构性证据。 这项工作关注的不是单一机器人任务,而是物理 AI 中人类数据如何转化为机器人能力这一更底层问题。论文中的结果仍以预印本形式呈现,相关真实机器人部署范围也限于文中任务设置但其技术路线表明,视觉后果可以作为跨具身动作对齐的锚点,减少直接运动学重定向对人工规则和特定平台的依赖。对于人形机器人基础模型而言,UniT 提供了一条把人类演示数据纳入策略学习和世界建模的统一表示路径。